01
传统框架的不足与 Parlant 的创新
传统的几百条规则、几十个工具与 demo 式饱和式上下文注入,往往在小规模测试中表现还不错,但在生产环境中就会立刻暴露三个致命问题:
规则冲突无法解决 :当多条规则同时适用时,LLM 会随机选择或混合执行,导致行为不可预测。例如,一个电商 Agent 同时面对”VIP 用户优先处理”和”高额订单需要二次确认”两条规则时,执行优先级完全依赖模型的随机性。
边缘情况覆盖不足 :你无法预知所有可能的用户输入组合。当遇到训练数据中罕见的场景时,Agent 会退化到通用回复模式,丢失业务特异性。
调试与优化成本高昂 :当 Agent 行为出现问题时,你无法确定是哪条规则失效了,只能重新调整整个系统提示,然后再次进行全量测试。
针对以上问题,Parlant 引入了 动态 规则注入 :将规则定义与规则执行分离,通过动态匹配机制确保只有最相关的规则被注入到 LLM 上下文中。
这个设计理念类似于现代 Web 框架中的路由系统——你不会在每个请求中加载所有路由处理器,而是根据 URL 动态匹配对应的处理逻辑。
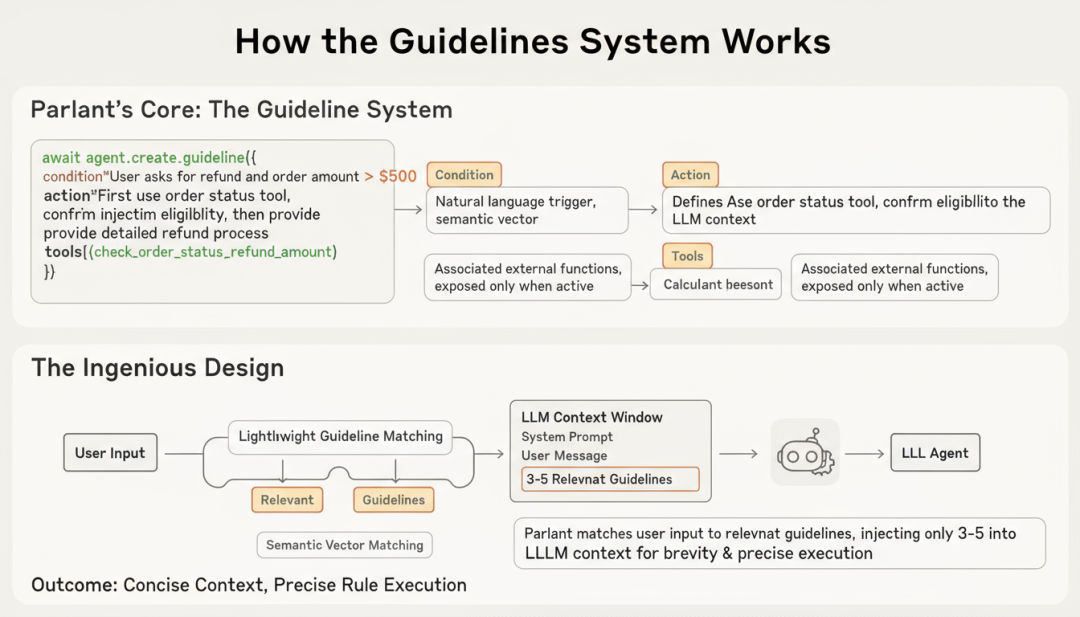
具体来说,Parlant 的核心是 Guidelines 系统,每条指南包含三个要素:
await agent.create_guideline(
condition="用户询问退款且订单金额超过500元",
action="先调用订单状态检查工具,确认是否符合退款条件,然后提供详细的退款流程说明",
tools=[check_order_status, calculate_refund_amount]
)
Condition(条件) :用自然语言描述触发场景,Parlant 会将其转换为语义向量进行匹配。
Action(行动) :明确定义 Agent 应该如何响应,这部分会在条件匹配时被注入到 LLM 上下文。
Tools(工具) :关联的外部函数,只有在指南激活时才会暴露给 Agent。
这个设计的精妙之处在于: Parlant 在每次用户输入时,会先进行一次轻量级的指南匹配过程,只将相关的 3-5 条指南注入到 LLM 上下文中 。这样既保持了上下文的简洁性,又确保了规则的精准执行。
在此基础上,Parlant 还引入了 自我批判机制 作为 双重保险 ,来提升规则遵循的一致性与可控性。其流程分为三步走:
- 生成候选回复:基于匹配的指南和对话上下文生成初步回复
- 合规性检查:将候选回复与激活的指南进行对比,验证是否完全遵循
- 修正或确认:如果发现偏差,触发修正流程;如果符合要求,输出最终回复
此外,传统 Agent 框架会将所有可用工具暴露给 LLM,从而导致两个问题:一是上下文膨胀,二是工具误用。Parlant 通过将工具与指南绑定,实现了条件化执行:
await agent.create_guideline(
condition="用户询问退款且订单金额超过500元",
action="先调用订单状态检查工具,确认是否符合退款条件,然后提供详细的退款流程说明",
tools=[check_order_status, calculate_refund_amount]
)
这种设计确保了工具调用的精准性,避免了 Agent 在不恰当的时机调用敏感 API。
02
动态规则注入的关键:Milvus
当我们深入 Parlant 的指南匹配机制时,会发现一个核心技术挑战: 如何在毫秒级延迟内,从数百甚至数千条指南中找到与当前对话最相关的 3-5 条 ?这就是向量数据库发挥作用的场景。
(1)语义匹配的技术实现
Parlant 的指南匹配本质上是一个语义检索问题。系统会将每条指南的 condition 字段转换为向量嵌入(Embedding),当用户输入到达时:
第一步,将用户消息和对话历史编码为查询向量
第二步,在指南向量库中执行相似度搜索
第三步,返回 Top-K 最相关的指南
第四步,将这些指南注入到 LLM 上下文中
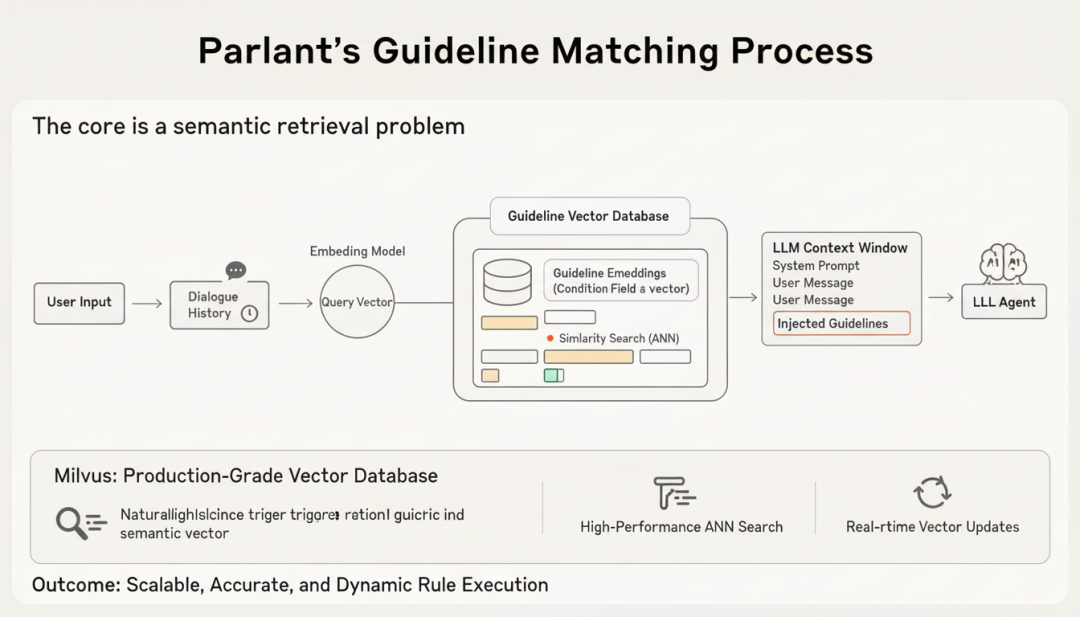
这个过程需要向量数据库具备三个核心能力: 高性能的近似最近邻搜索(ANN)、灵活的元数据过滤、以及实时的向量更新 。Milvus 在这三个维度上都提供了生产级的支持。
(2)Milvus 在 Agent 系统中的实际应用
以一个金融服务 Agent 为例,假设系统中定义了 800 条业务指南,覆盖账户查询、转账、理财产品咨询等场景。使用 Milvus 作为指南存储层的架构如下:
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
import parlant.sdk as p
# 连接Milvus
connections.connect(host="localhost", port="19530")
# 定义指南集合的Schema
fields = [
FieldSchema(name="guideline_id", dtype=DataType.VARCHAR, max_length=100, is_primary=True),
FieldSchema(name="condition_vector", dtype=DataType.FLOAT_VECTOR, dim=768),
FieldSchema(name="condition_text", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="action_text", dtype=DataType.VARCHAR, max_length=2000),
FieldSchema(name="priority", dtype=DataType.INT64),
FieldSchema(name="business_domain", dtype=DataType.VARCHAR, max_length=50)
]
schema = CollectionSchema(fields=fields, description="Agent Guidelines")
guideline_collection = Collection(name="agent_guidelines", schema=schema)
# 创建HNSW索引以实现高性能检索
index_params = {
"index_type": "HNSW",
"metric_type": "COSINE",
"params": {"M": 16, "efConstruction": 200}
}
guideline_collection.create_index(field_name="condition_vector", index_params=index_params)
在实际运行时,当用户输入"我想把10万元转到我妈妈的账户"时,系统会:
- 向量化查询 :将用户输入转换为 768 维向量
- 混合检索 :在 Milvus 中执行向量相似度搜索,同时应用元数据过滤(如 business_domain=“transfer”)
- 结果排序 :根据相似度分数和 priority 字段综合排序
- 上下文注入 :将 Top-3 匹配的指南的 action_text 注入到 Parlant Agent 的上下文中
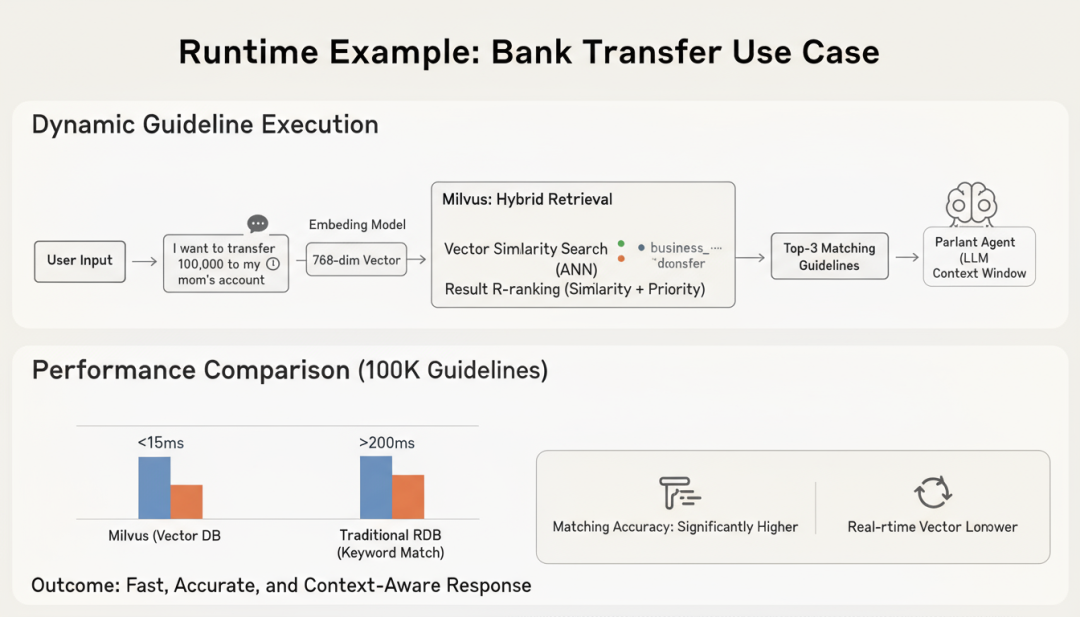
这个过程在 Milvus 中的 P99 延迟通常低于 15ms ,即使指南库规模达到 10 万条。相比之下,如果使用传统关系型数据库存储指南并通过关键词匹配,延迟会超过 200ms,且匹配精度显著下降。