0. 背景
随着现在各种软件系统的复杂度越来越高,特别是部署到云上之后,再想登录各个节点上查看各个模块的 log,基本是不可行了。因为不仅效率低下,而且有时由于安全性,不可能让工程师直接访问各个物理节点。而且现在大规模的软件系统基本都采用集群的部署方式,意味着对每个 service,会启动多个完全一样的 POD 对外提供服务,每个 container 都会产生自己的 log,仅从产生的 log 来看,你根本不知道是哪个 POD 产生的,这样对查看分布式的日志更加困难。
所以在云时代,需要一个收集并分析 log 的解决方案。首先需要将分布在各个角落的 log 收集到一个集中的地方,方便查看。收集了之后,还可以进行各种统计分析,甚至用流行的大数据或 maching learning 的方法进行分析。当然,对于传统的软件部署方式,也需要这样的 log 的解决方案
ELK 就是这样的解决方案,而且基本就是事实上的标准。ELK 是三个开源项目的首字母缩写,如下:
E: Elasticsearch L: Logstash K: Kibana
Logstash 的主要作用是收集分布在各处的 log 并进行处理;Elasticsearch 则是一个集中存储 log 的地方,更重要的是它是一个全文检索以及分析的引擎,它能让用户以近乎实时的方式来查看、分析海量的数据。Kibana 则是为 Elasticsearch 开发的前端 GUI,让用户可以很方便的以图形化的接口查询 Elasticsearch 中存储的数据,同时也提供了各种分析的模块,比如构建 dashboard 的功能。
我个人认为将 ELK 中的 L 理解成 Logging Agent 更合适。Elasticsearch 和 Kibana 基本就是存储、检索和分析 log 的标准方案,而 Logstash 则并不是唯一的收集 log 的方案,Fluentd 和 Filebeats 也能用于收集 log。所以现在网上有 ELK,EFK 之类的缩写。
一般采用的架构如下图所示。通常一个小型的 cluster 有三个节点,在这三个节点上可能会运行几十个甚至上百个容器。而我们只需要在每个节点上启动一个 logging agent 的实例(在 kubernetes 中就是 DaemonSet 的概念)即可。
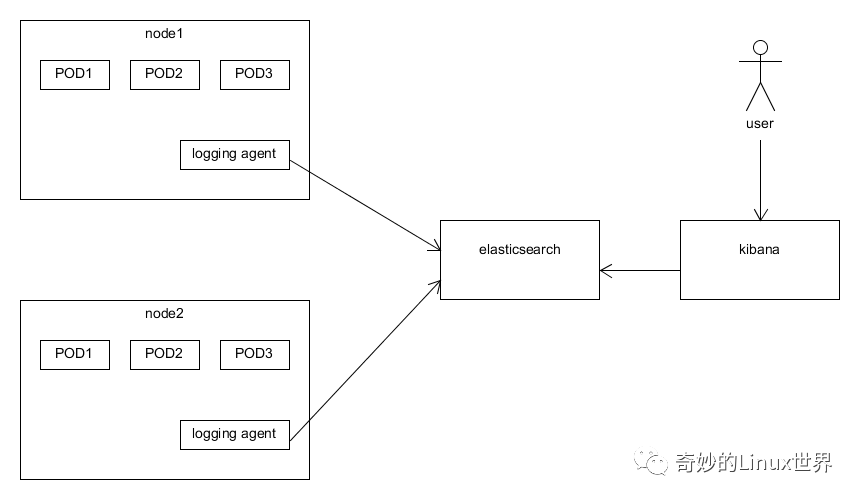
1. ELK 框架
ELK 是 Elasticsearch、Logstash 和 Kibana 三个开源工具的缩写,广泛用于日志的收集、存储、分析和可视化。
组成:
- Elasticsearch :分布式搜索引擎,用于存储和检索日志数据。
- Logstash :日志收集和处理工具,支持多种数据源和格式。
- Kibana :数据可视化工具,用于展示和分析日志数据。
特点:
- 强大的搜索和分析能力 :Elasticsearch 提供了高效的全文搜索和复杂查询功能。
- 灵活的日志收集 :Logstash 支持多种输入源(如文件、数据库、消息队列等)和输出目标。
- 丰富的可视化 :Kibana 提供了多种图表和仪表盘,方便用户直观分析日志。
- 扩展性强 :可以通过插件扩展功能,例如 Beats(轻量级数据采集器)可以替代 Logstash 进行日志收集。
适用场景:
- 大规模日志收集和分析。
- 需要复杂查询和全文搜索的场景。
- 需要实时监控和可视化的场景。
缺点:
- 部署和维护成本较高,尤其是 Elasticsearch 的集群管理。
- 对资源(CPU、内存、存储)消耗较大。
2 EFK 框架
L 换成了 Fluentd
即 Elasticsearch、Fluentd、Kibana
Filebeats、Logstash、Fluentd 三者的区别和联系
这里有必要对 Filebeats、Logstash 和 Fluentd 三者之间的联系和区别做一个简要的说明。Filebeats 是一个轻量级的收集本地 log 数据的方案,官方对 Filebeats 的说明如下。可以看出 Filebeats 功能比较单一,它仅仅只能收集本地的 log,但并不能对收集到的 Log 做什么处理,所以通常 Filebeats 通常需要将收集到的 log 发送到 Logstash 做进一步的处理。
Filebeat is a log data shipper for local files. Installed as an agent on your servers, Filebeat monitors the log directories or specific log files, tails the files, and forwards them either to Elasticsearch or Logstash for indexing
Logstash 和 Fluentd 都具有收集并处理 log 的能力,网上有很多关于二者的对比,提供一个写得比较好的文章链接如下。
功能上二者旗鼓相当,但 Logstash 消耗更多的 memory,对此 Logstash 的解决方案是使用 Filebeats 从各个叶子节点上收集 log,当然 Fluentd 也有对应的 Fluent Bit。
另外一个重要的区别是 Fluentd 抽象性做得更好,对用户屏蔽了底层细节的繁琐。作者的原话如下:
Fluentd’s approach is more declarative whereas Logstash’s method is procedural. For programmers trained in procedural programming, Logstash’s configuration can be easier to get started. On the other hand, Fluentd’s tag-based routing allows complex routing to be expressed cleanly.
虽然作者说是要中立的对二者(Logstash 和 Fluentd)进行对比,但实际上偏向性很明显了:)。本文也主要基于 Fluentd 进行介绍,不过总体思路都是相通的。
额外说一点,Filebeats、Logstash、Elasticsearch 和 Kibana 是属于同一家公司的开源项目,官方文档如下:
Fluentd 则是另一家公司的开源项目,官方文档如下:
3. ALG 框架
ALG 是 Alloy 、Loki 和 Grafana 的组合,是一种轻量化的日志收集和分析框架,专注于高效性和易用性。
组成:
- Alloy :一个轻量级的日志收集器,用于从各种来源收集日志数据。
- Loki :由 Grafana Labs 开发的日志聚合系统,专注于高效的日志存储和查询。
- Grafana :数据可视化工具,用于展示和分析日志数据。
特点:
- 轻量化和高效 :Loki 使用索引和标签来存储日志,相比 Elasticsearch 更节省资源。
- 低成本存储 :Loki 专注于日志的存储和查询,不存储原始日志的全文索引,因此存储成本较低。
- 强大的可视化 :Grafana 提供了丰富的时间序列数据展示功能,适合监控和告警场景。
- 易于集成 :Alloy 和 Loki 的设计使其易于与其他工具(如 Prometheus)集成。
适用场景:
- 需要轻量化和高效日志存储的场景。
- 需要低成本日志存储和查询的场景。
- 需要实时监控和可视化的场景。
缺点:
- Loki 的查询功能相对 Elasticsearch 较弱,不支持复杂的全文搜索。
- 对于需要复杂日志分析的场景可能不够灵活。
4. ELK 和 ALG 的对比
| 特性 | ELK、EFK | ALG |
|---|---|---|
| 核心组件 | Elasticsearch, Logstash/Fluentd, Kibana | Alloy, Loki, Grafana |
| 日志存储 | Elasticsearch | Loki |
| 日志收集 | Logstash 或 Beats 或 Fluentd | Alloy |
| 可视化工具 | Kibana(日志分析为主) | Grafana(时间序列数据为主) |
| 适用场景 | 日志搜索、分析和可视化 | 轻量化日志存储和实时监控 |
| 资源消耗 | 较高 | 较低 |
| 部署复杂度 | 较高 | 较低 |
| 查询能力 | 强大的全文搜索和复杂查询 | 基于标签的高效查询 |
| 存储成本 | 较高 | 较低 |
5. 选择建议
- 如果需要强大的日志搜索和分析能力,选择 ELK 。
- 如果需要轻量化、低成本的日志存储和实时监控,选择 ALG 。
- 如果资源有限,且主要关注时间序列数据的监控和告警,ALG 是更好的选择。
- 如果需要复杂的日志分析和全文搜索,ELK 更适合。
根据具体需求和场景,也可以将两者结合使用,例如使用 Loki 存储日志并用 Grafana 进行可视化,同时使用 Elasticsearch 处理需要复杂查询的日志数据。