redis 集群下, slot 分配原则
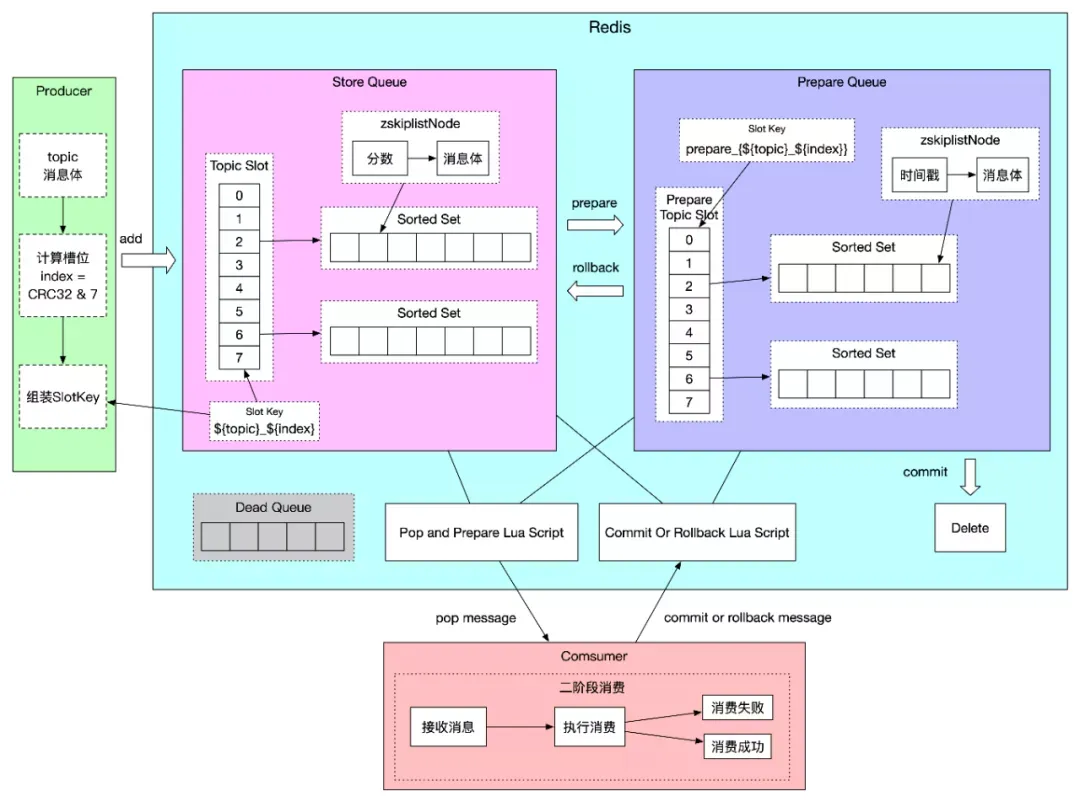
在后面将会详细介绍二阶段消费的实现思路,这里重点介绍下 PrepareQueue 的存储设计。StoreQueue 中每一个 Slot 对应 PrepareQueue 中的 Slot,PrepareQueue 的 SlotKey 设计为 prepare_{#{topic}#{index}}。PrepareQueue 采用 Sorted Set 作为存储,消息移动到 PrepareQueue 时刻对应的(秒级时间戳*1000+重试次数)作为分数,字符串存储的是消息体内容。这里分数的设计与重试次数的设计密切相关,所以在重试次数设计章节详细介绍。
PrepareQueue 的 SlotKey 设计中需要注意的一点,由于消息从 StoreQueue 移动到 PrepareQueue 是通过 Lua 脚本操作的,因此需要保证 Lua 脚本操作的 Slot 在同一个 Redis 节点上,如何保证 PrepareQueue 的 SlotKey 和对应的 StoreQueue 的 SlotKey 被 hash 到同一个 Redis 槽中呢。Redis 的 hash tag 功能可以指定 SlotKey 中只有某一部分参与计算 hash,这一部分采用{}包括,因此 PrepareQueue 的 SlotKey 中采用{}包括了 StoreQueue 的 SlotKey。
时间戳容纳重试次数
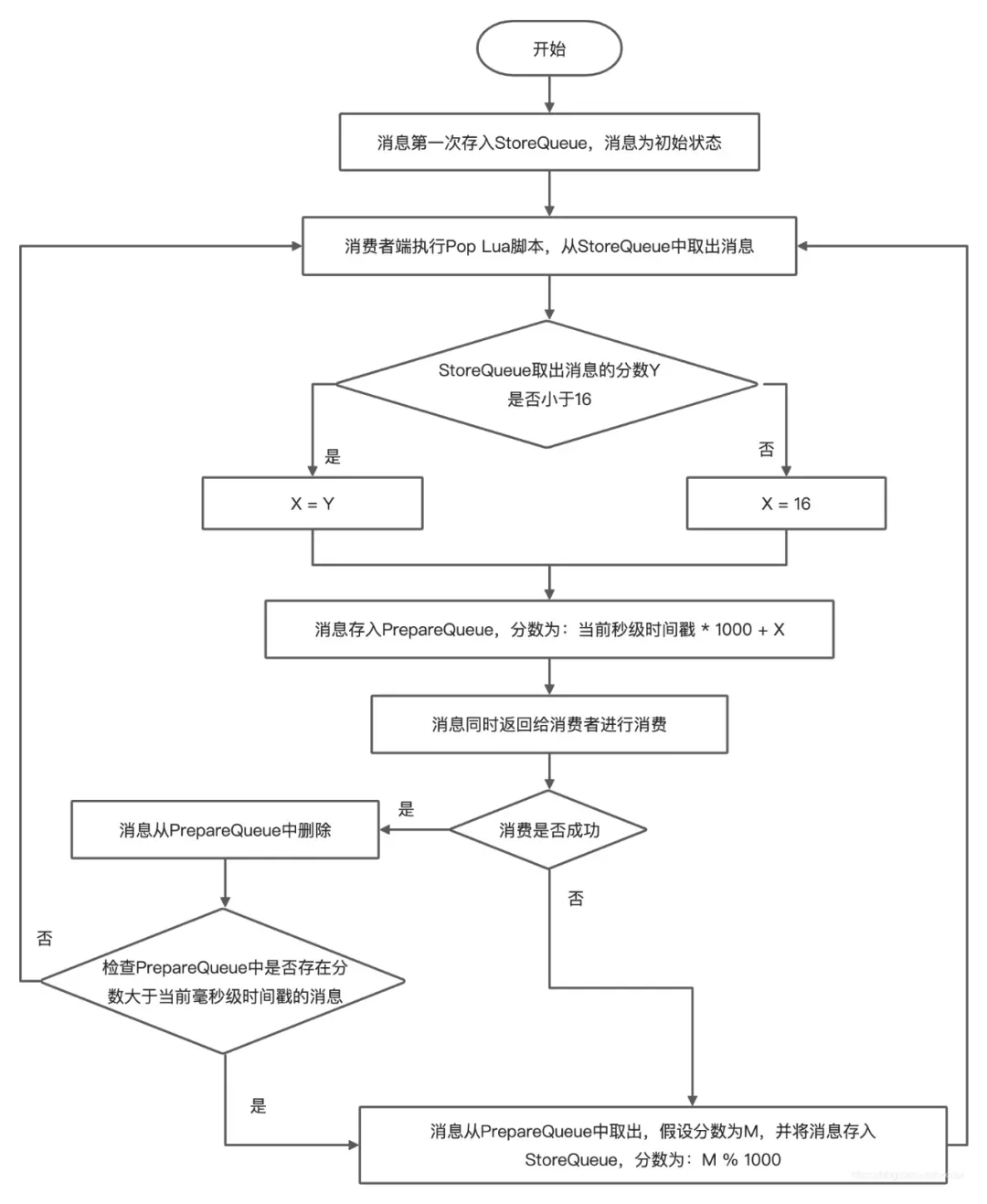
因此 PrepareQueue 的分数设计为:秒级时间戳*1000+重试次数。定时消息首次存储到 StoreQueue 中的分数表示消费时间戳,如果消息消费失败,消息从 PrepareQueue 回滚到 StoreQueue,定时消息存储时的分数都表示剩余重试次数,剩余重试次数从 16 次不断降低最后为 0,消息进入死信队列。消息在 StoreQueue 和 PrepareQueue 之间移动流程如下:
其他方案
1. 位操作方案
利用时间戳的低位比特来存储重试次数:
最终值 = (时间戳 << N位) | 重试次数
其中N是分配给重试计数器的位数。例如:
如果分配8位给重试计数,那么:
最终值 = (时间戳 << 8) | 重试次数(0-255)
这样做的优点是操作简单高效,缺点是会减少时间戳的精度。
2. 小数部分存储
如果使用浮点数表示时间戳,可以将重试次数存储在小数部分:
最终值 = 时间戳 + (重试次数 / 10000)
3. 字符串拼接
将时间戳和重试次数拼接成一个字符串:
"时间戳_重试次数",例如:"1619823945_3"
选择合适的方案
选择哪种方案取决于您的具体需求:
- 如果对时间精度要求不高,但性能要求高,可以选择位操作方案
- 如果需要保持原始时间戳的精度,可以选择小数部分存储或字符串拼接方案
- 如果系统需要处理超大量的重试,需要确保重试次数的位数足够
您是否需要我详细解释其中某个方案的具体实现,或者有关于特定应用场景的问题?