DuckDB 为什么这么快?
DuckDB 从优化器,执行器,操作符,和存储等各个环节都利用了业界最新的技术,并凭借强大的工程能力,实现了单机复杂查询的极致性能,超过了同类分析型数据库。这里仅对 DuckDB 的优化点做一个简单的概述,具体的实现细节可以参考引用文档。
优化器
在很少甚至没有统计信息的情况下,连接顺序优化器(join order optimzier)【3】通过减少连接过程中处理的中间元组数量,显著提升了多表 join 查询性能。具体优化点如下:
- 通过减少多表连接时的中间结果规模,提升复杂查询的执行效率;
- 在 Join Order 枚举过程中,采用高效的搜索策略,平衡探索空间与计算开销,避免传统动态规划方法的高复杂度问题;
- 轻量化统计依赖:结合轻量级信息生成优化策略,降低对传统统计信息的依赖,适应实时分析场景。
执行器
2.1 列向量化执行(columnar-vectorized query execution engine)
DuckDB 采用列向量化执行提升查询的性能。
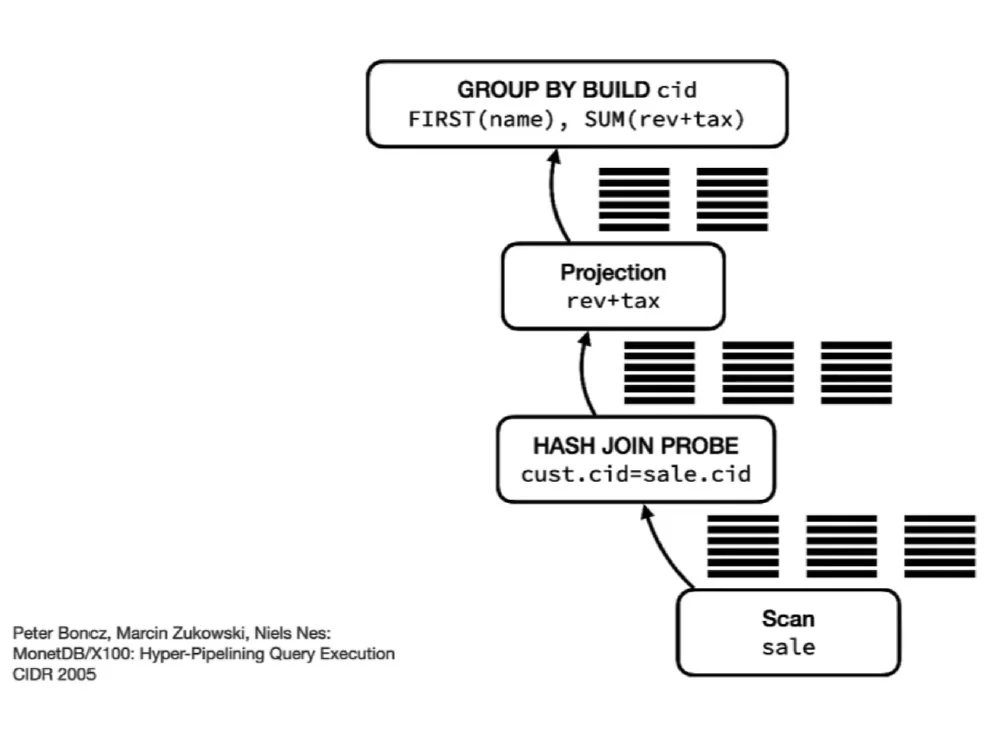
[4]
向量化查询执行指的是数据库引擎中的一种方法,它通过批量处理数据而不是逐行处理数据来增强查询性能。这种方法通过利用现代 CPU 架构及其执行单指令、多数据 (SIMD) 操作的能力,提高了 CPU 的数据处理效率。
向量化查询执行通过将称为向量的数据块加载到 CPU 缓存中,并在这些数据上执行批量操作来运行。其主要特点包括:
- 批量处理:以大块数据处理,减少与处理单个数据点相关的开销。
- 单指令多数据 (SIMD) 优化:通过同时对多个数据点执行相同的操作来最大限度地提高效率。
- 列式读写:仅处理查询相关的列,而不是整个数据集,从而简化操作。
2.2 基于推送的执行(push based execution)
DuckDB 采用推送的执行模型提高并行度从而提升查询的性能。
基于推送的处理是一种查询处理模型,数据从底层的操作符推送到上层的操作符,整体执行的控制流是自底向上。
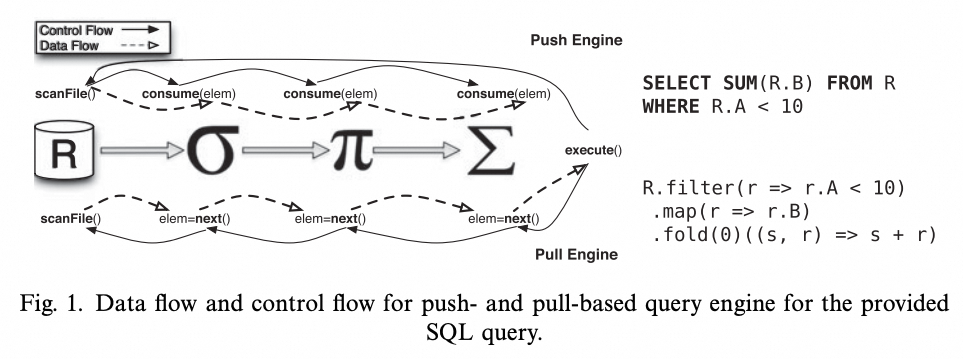
[5]
数据其中系统中的每个操作符自行决定是否并行执行,而不是依赖于集中执行器。DuckDB 采用这一模型,是因为原来的基于拉取(pull based execution)的向量化查询处理在添加额外操作符时遇到了挑战。基于推送的处理模型允许更灵活和高效地同时执行多个管道,提高了系统处理复杂并行性和高效操作的能力。
拉取模型往往需要在计划生成阶段就决定好并行度,DuckDB 的推送模型实现了 Morsel-Driven Parallelism:
- 查询被划分为多个 pipeline,即执行计划可以划分为多个部分并行执行;
- 每个操作符自行决定是否并行执行,同时操作符间的并行互相能感知到。
下图是一个三张表 join 的例子,左边为关系代数表达式,右边为并行化执行的过程。
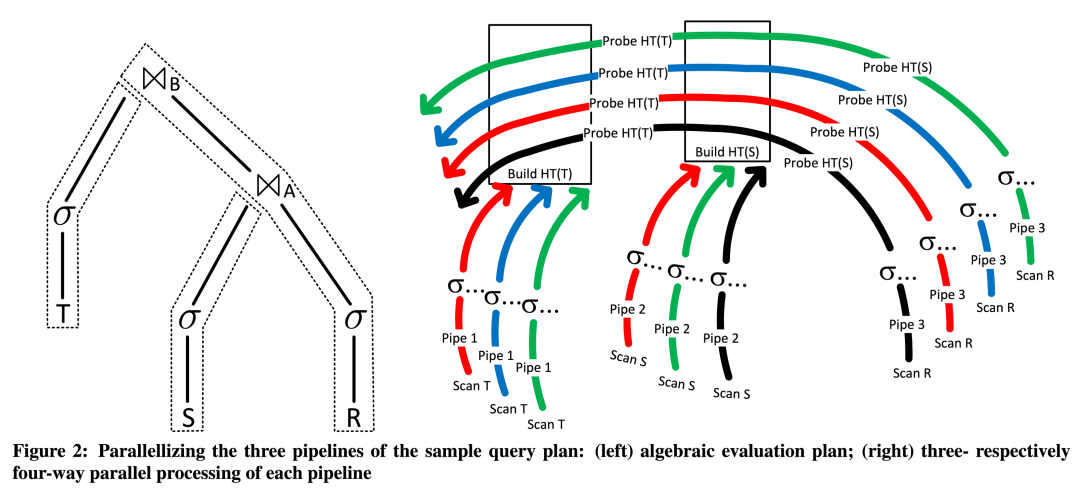
推送模型还开辟了额外优化和更细粒度控制系统的可能性。其中包括使用向量缓存(Vector Cache)在操作符之间缓冲结果,直到填满向量。此外,扫描共享(Scan Sharing)涉及在有向无环图(DAG)计划中将一个子操作符的结果推送给多个父操作符。在中央位置存储状态还支持反压(Backpressure)/异步 IO(Async IO),即在缓冲区满时或等待远程 IO 时暂停操作符执行。这种细粒度控制使得在数据库系统内能够进行更高效和优化的查询处理。
操作符(operator)优化
DuckDB 针对执行器中的核心算子(包括 sort,aggregationg 等等)做了大量优化,以此来提升查询性能。
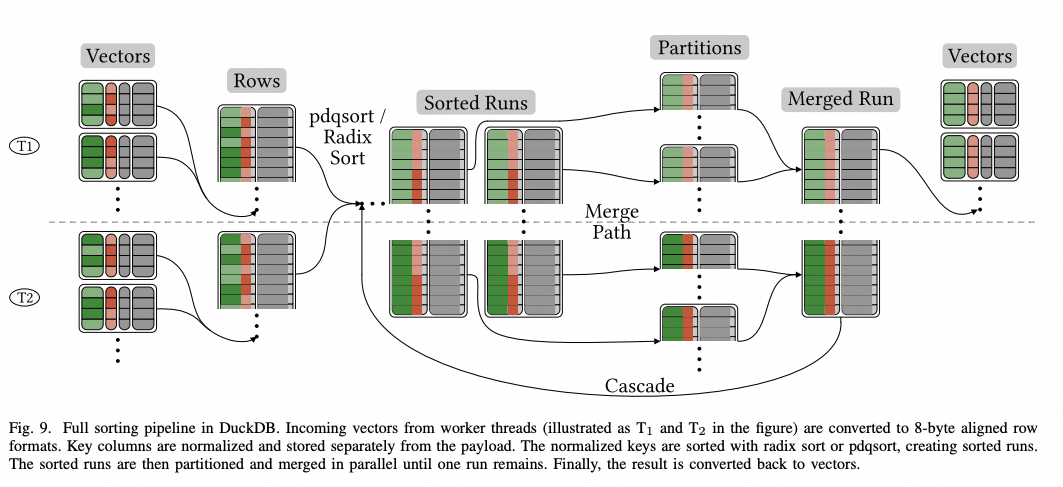
3.1 sort【7】【8】
DuckDB 针对列存排序做了多项优化,包括利用了索引避免排序,内存与磁盘排序的切换,并行化排序,和延迟物化等等技术手段,实现了极致的排序性能。
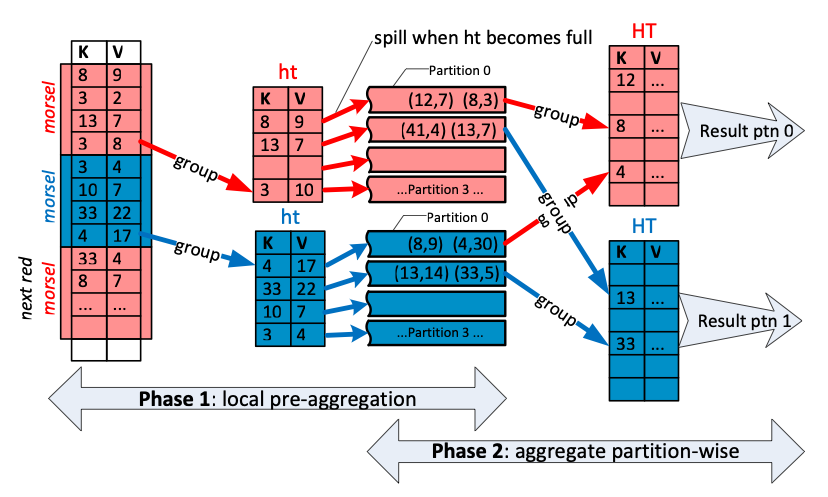
3.2 hash aggregation【9】【10】
针对 hash aggregation 操作符,采用分区和并行化的优化,同时考虑内存和磁盘的交换情况,提升执行性能。
RDS DuckDB 架构&性能
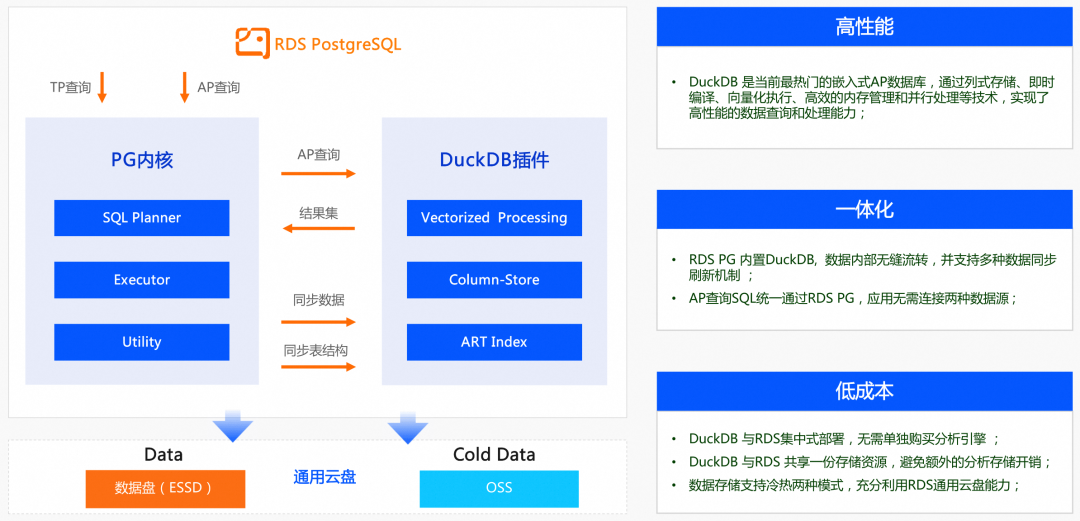
从以上架构图可以看到:
- 数据同步:PG 中全量行存数据导入 rds_duckdb 插件中,转换为列存数据,并开启增量数据同步。其中增量同步基于 PG 原生逻辑复制实现。
- 查询处理:分析查询路由到 rds_duckdb 插件中,经过向量化并行执行算子产生查询结果,然后经过类型转换返回给客户端。