kafka 实现
当前比较常规的低延迟的延迟队列实现主要有两种:通过 消息队列(MQ) 实现 以及 通过 Redis 来实现。由于 Redis 的持久化机制导致其对消息的可靠性无法保证,不予考虑,因此主要考虑使用 MQ 来实现延迟队列。常用的几款 MQ 的对比如表 2-1 所示:
| RabbitMQ | RocketMQ | Kafka | |
| 消息吞吐量 | 低 | 高 | 极高 |
| 消息延迟 | 低 | 中 | 中 |
| 支持延迟消息 | 是 | 是 | 否 |
| 是否支持任意延迟时间 | 否,可根据配置创建多个延迟级别的队列 | 是(5.x以上版本),5.x以下支持18个延迟级别 | 否 |
表 2-1 消息中间件对比
在前文已经提到,由于 RabbitMQ 的吞吐量太低,无法满足日益增长的业务需求,所以不予考虑。从表 2-1 可以看出,RocketMQ 和 Kafka 的吞吐和消息延迟都很低,而且 RocketMQ 还已经支持延迟队列,最高版本还支持任意延迟等级的延迟队列,能够满足业务高吞吐、低延迟的要求,理应是最佳选择。但最新版本的 RocketMQ 如果选择支持任意延迟等级的功能,其吞吐量会相较于之前下降一倍以上,另外目前公司内部未使用 RocketMQ,引入新的中间件会引入额外的风险以及增加运维成本,所以这个选项也先被搁置。
目前公司内部主要用的消息队列是 Kafka,Kafka 在吞吐和延迟上能够满足业务对延迟队列的需求,但是它不支持延迟队列,因此我们考虑是否可以基于 Kafka 来自研一套延迟队列。基于 Kafka 实现延迟队列虽然要自己实现延迟消息的管理与投递,但它的优势有:
(1) 延迟队列服务可以独立于 Kafka broker,对 broker 不会引入额外的压力;
(2) 延迟队列服务是可以横向扩容的,理论上可以支持任意级别的延迟时间,而且还能保持高吞吐特性;
(3) 基于 Kafka 实现延迟队列,无需引入新的中间件,无额外的运维压力;
(4) 自研的延迟队列更易于维护和更新迭代。
基于以上考虑,我们决定基于 Kafka 自行实现一套延迟队列。
实现方案
核心原理
延迟队列的核心实现原理如图 3-1 所示,其原理与 RabbitMQ 以及 RocketMQ 旧版实现相似,都是针对不同的延迟等级创建队列,增设调度服务用于定时消费带有延迟属性的队列,并将消费到的数据投递到目标队列。这里每个队列都是对应一个个 Kafka topic,业务服务将消息投递到对应的队列中(也就是不同延迟等级对应的 topic 上),由延迟调度服务将各个队列中的数据准时地投递到业务实际目标的 topic 中,之后业务服务再消费目标 topic 中的数据进行下一步处理。
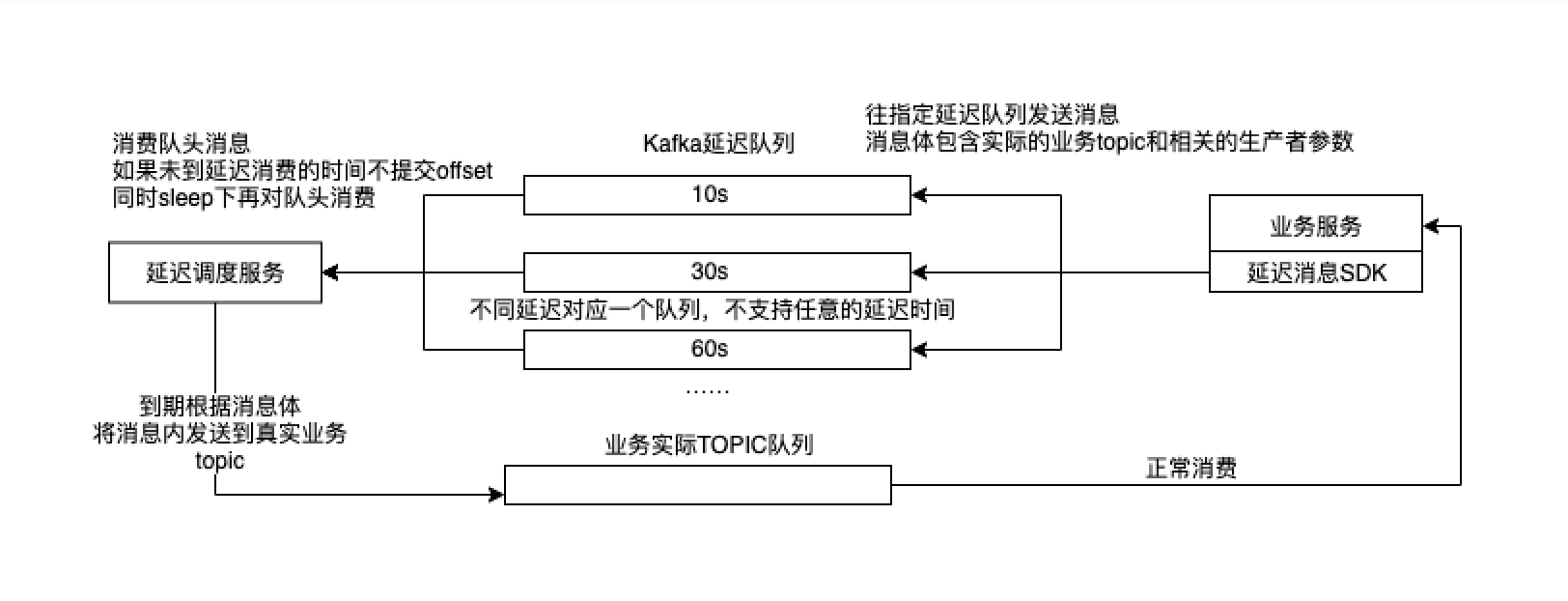
图 3-1 延迟队列实现原理
整体架构
延迟队列实现的整体架构图如图 3-2 所示。其中核心部分主要有 3 个模块:Manager 服务、延迟调度服务 以及 SDK(延迟队列客户端)。它们的各自负责的功能介绍如下:
-
Manager 服务
延迟队列的管理平台,负责对整个延迟队列进行监控和管理,如业务接入、队列健康情况监控等等。 -
延迟调度服务
延迟调度服务是延迟队列实现的核心,负责将延迟等级队列中的数据准时地转发至业务实际 topic 中。为了让业务之间不互相影响,在队列之上引入了分组的概念,每个业务域可以独立配置一个组,组与组之间的延迟队列是相互独立的。延迟队列的每个延迟等级都与 Kafka 的 topic 相对应,是 1:N 的关系,确保每个延迟等级的吞吐可以无限扩展。延迟调度服务在运行过程中会上报关键指标(转发延时、各节点处理耗时等),助于问题排查和稳定性监控。 -
SDK(延迟队列客户端)
延迟队列客户端是用于协助业务将需要延迟处理的数据写入到延迟队列中,这里将延迟队列客户端封装为 SDK,方便业务接入。
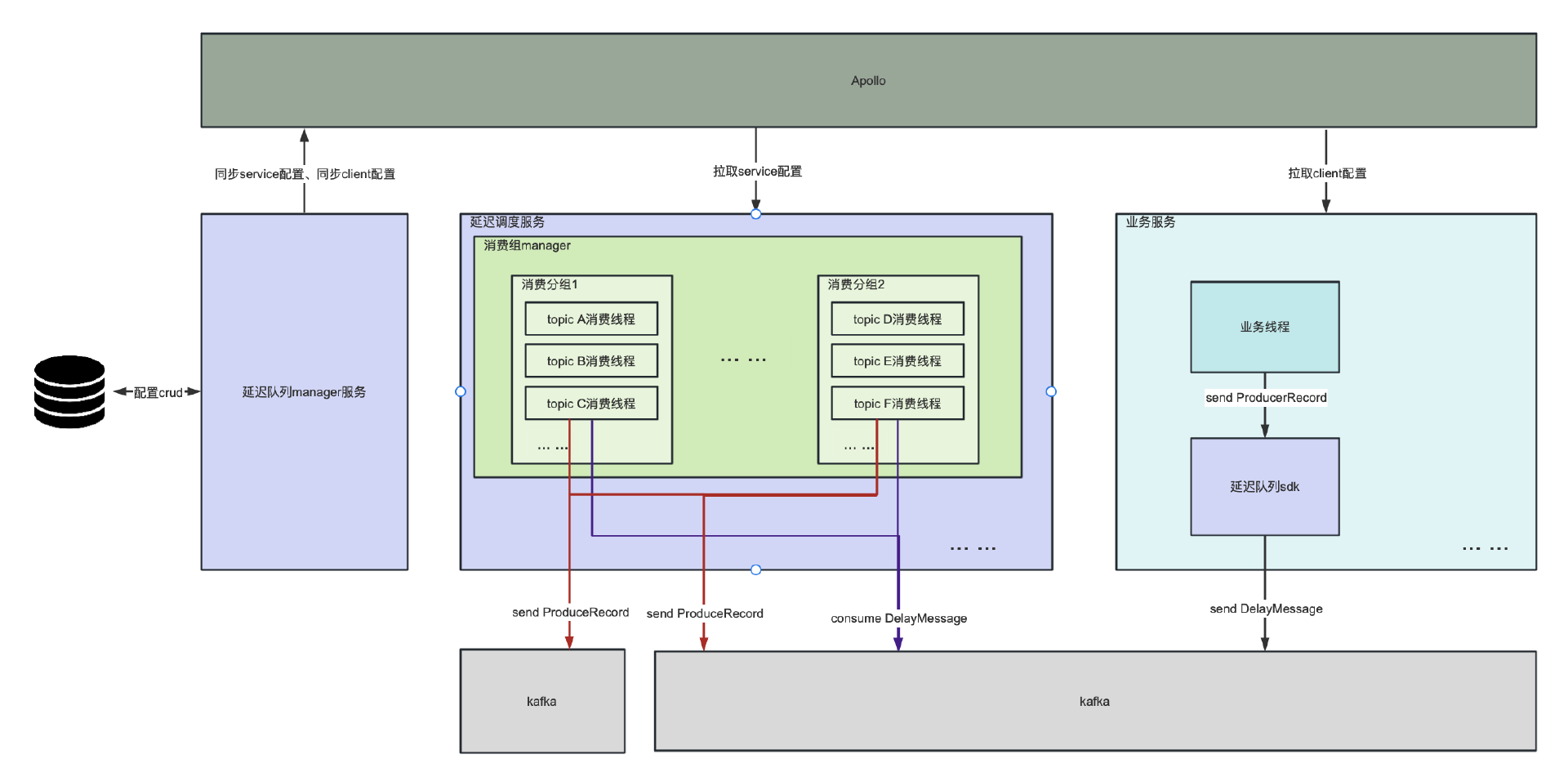
图 3-2 整体架构图
核心设计点
消息高效转发与低延迟
延迟队列实现的核心点是要将业务写入到不同延迟等级的队列中的数据准时地投递到目标 topic。这里「准时」的定义是在消息延迟时间未到时不能进行消息投递,当延迟时间到达时,要快速将数据投递到目标 topic,从而降低延迟时间。
最初我们实现数据转发的方案是通过 KafkaConsumer 的 pause、resume 来对分区消费的暂停、恢复。kafka-clients 提供了两个 API:KafkaConsumer#pause、KafkaConsumer#resume,通过这两个 api 能够对未到达消息发送的分区进行暂停,并在发送时刻唤醒转发。后来经过测试发现,进行 pause 后 resume 的分区并不能及时消费到消息,而是在 resume 后的 100~500ms 才能获取到消息,这大大增加了延时时间,不满足「低延迟」的要求。
通过对 Kafka-clients 的源码和版本分析发现:在 kafka-clients 2.3 及以下版本中,对分区进行 pause 后,本地缓冲区中的分区消息失效,再进行 resume 时,需要等待缓冲区消息消费完成后重新 fetch 消息,增加了网络消耗,耗时远大于本地内存处理。在 kafka-clients 2.4 及以上版本中,调整了这部分逻辑,pause 的分区在过滤后重新放回本地缓冲区,在未触发重平衡的情况下,resume 后仍可以从内存中消费。图 3-3 列出了 kafka-clients 2.3.1 版本和 2.4.0 版本代码的差异(其中左图为 2.3.1 版本,右图为 2.4.0 版本)。
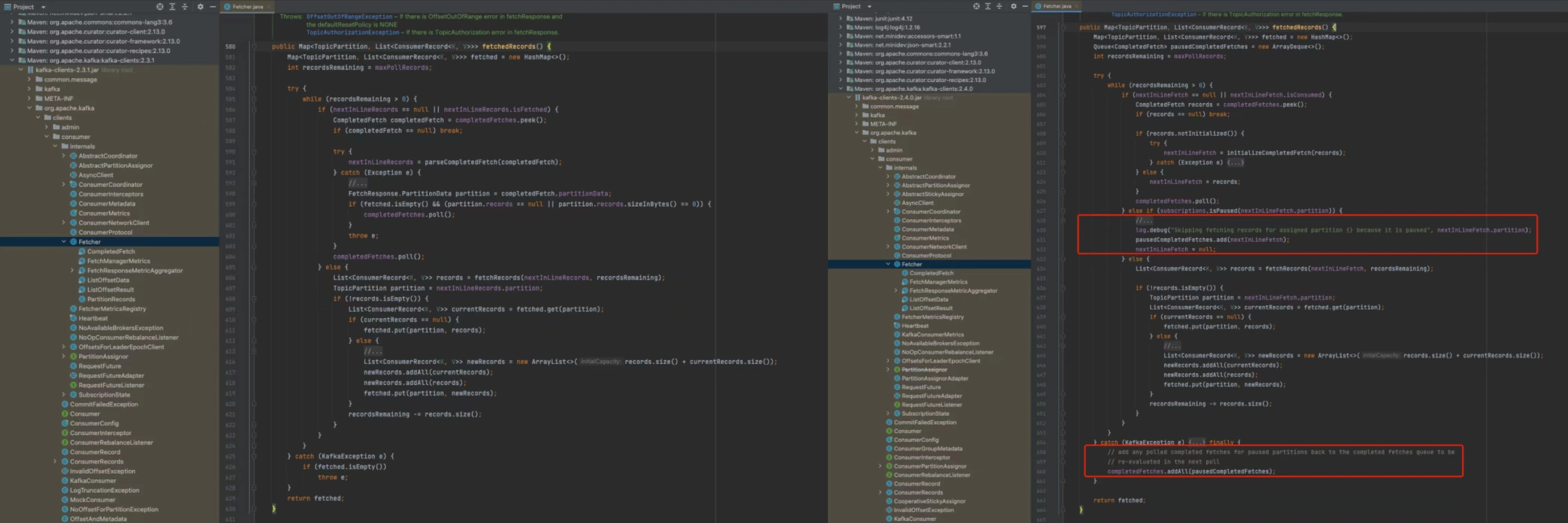
图 3-3 kafka-clients 差异代码对比
发现问题后,我们采用了另一种方式:线程内休眠等待。这种实现方式有两个注意点:
- 休眠时间的长短设置。休眠时间过长,会导致延迟上升。休眠时长过短,会导致频繁无效拉取,导致资源浪费;
- 消息投递的准确性。正常情况下一个消费组会消费同一个队列的多个分片,这里如果消费线程出现休眠等待,会导致所有分片的数据无法被投递。 针对休眠时间的问题,为了能够降低延迟时间,我们采用根据最近一条待投递的消息的投递时间距离当前时间的长短来确定休眠时间。另外为了避免过长的休眠时间导致消费组发生重平衡,所以也加入了固定时长休眠机制。通过这两种机制结合确保低延迟,同时也不会造成重平衡。
针对消息投递准确性问题的实现方案是让每个 topic 都只有一个分片,每个 topic 对应一个消费组。这样如果第一条数据都不需要被投递,那么这个队列就没有消息需要被投递,也不存在该被投递的消息因为休眠而无法被准时投递出去的问题。另外在配置关系上将延迟队列等级与 topic 的对应关系改为 1:N,可以解决由于每个 topic 只有一个分片而引起的写入性能瓶颈。这样做的好处不仅仅是确保了消息的准确投递,理论上通过增加延迟调度服务和扩展队列对应的 topic,能够让延迟队列支持任意时间的延迟等级,以及支持每个延迟等级的吞吐无上限。
支持消费任务的负载均衡
上文提到可以通过增加延迟调度服务的实力以及扩展延迟队列对应的 topic 将对应的延迟级别以及吞吐提升上去。但当延迟调度服务的实例和 topic 数增加到一定程度后就会出现一个问题,就是各个延迟调度服务分配到的 topic 会出现不均衡的情况,如图 3-4 所示。这样会导致即使增加延迟调度服务的实例,整个系统也会出现性能瓶颈。
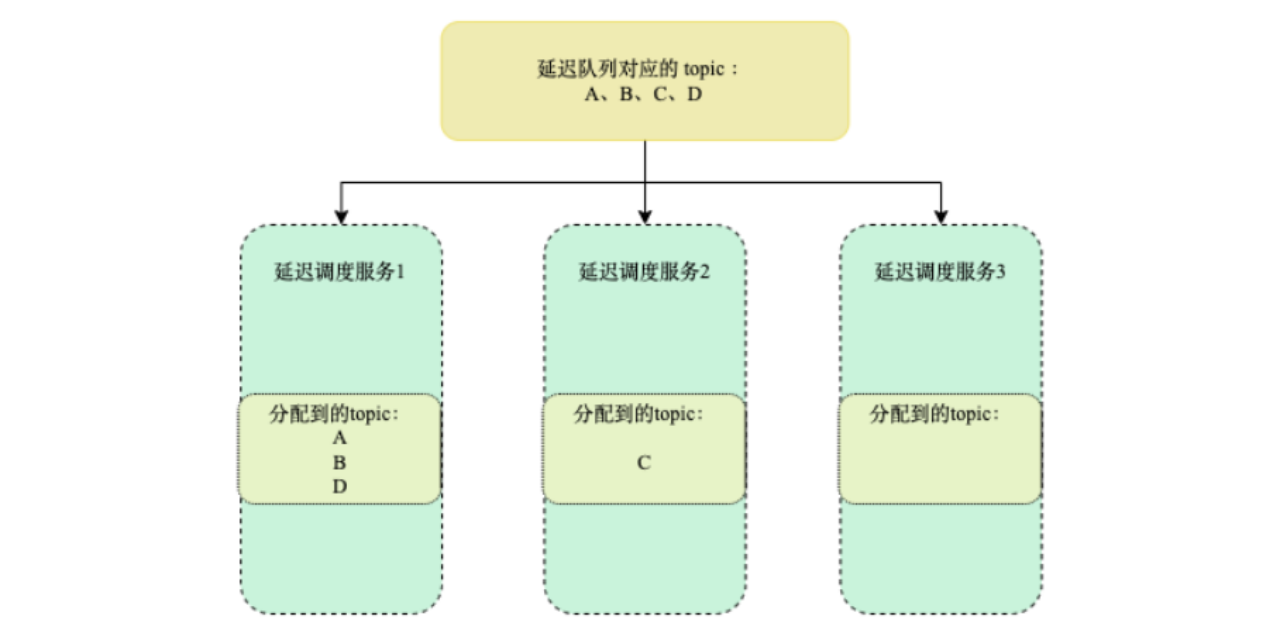
图 3-4 topic 分配不均 因此需要由一个支持消费任务负载均衡的方案,将多个 topic 的消费任务均匀地分配给各个延迟调度服务实例中,确保各个延迟调度服务之间压力近似。具体方案的实现逻辑如图 3-5 所示:
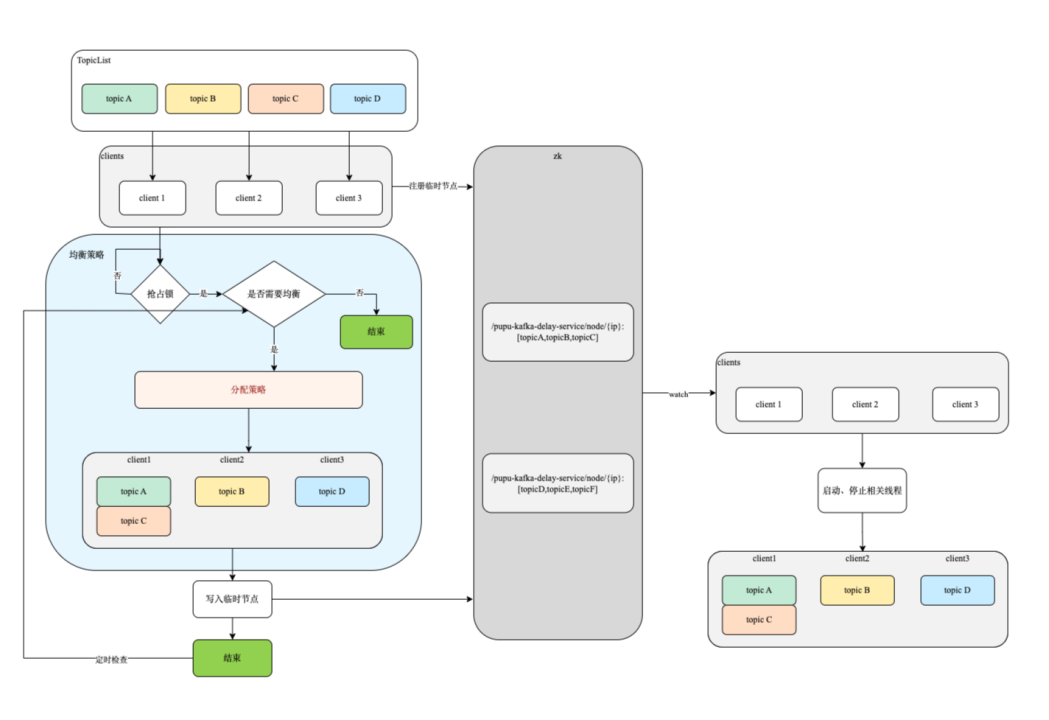
图 3-5 负载均衡实现逻辑 流程说明:
- 延迟调度服务实例启动后,需要向 ZK 注册临时节点;
- 延迟分配策略由其中一个延迟调度实例完成,各个延迟调度服务实例通过抢占锁的方式来确定由谁执行;
- 负责执行调度策略的实例根据当前需要消费的总 topic 数以及延迟调度实例数,在结合队列类型,将 topic 分配给各个实例,并将结果写入 zk 中;
- 各延迟调度服务实例监听到分配结果变更后就会将结果拉取下来,并启动对应的消费组消费对应 topic 的消息;
- 当有新的延迟调度实例加入或者老的宕机后,会重新开启新的一轮分配。新的分配逻辑与之前近似,只是会结合当前已有分配情况进行重新调整,避免大面积的消费组重启。
消息可靠性的保证
作为一款通用的延迟队列,我们需要提供消息可靠性的保障,确保数据不丢失。为此,基于 Kafka 特性,延迟队列对外提供两种语义的配置:
-
至少一次:确保消息不丢且保证有序,但有可能重复投递;
-
有且仅有一次:确保消息不丢且不重复投递,并保证有序。这种方案在吞吐上有较多的损耗,且该语义是基于 Kafka 事务机制来实现,包含了 Kafka 事务缺陷。 除此之外,为了保证数据不丢失,还对于延迟调度服务进行了以下优化:
-
生产者 acks 设置为 all ;
-
消费具有延迟属性的延迟消息,offset 在消息成功转发回调中处理提交。这样即使在断电等极端情况下,仍能在系统恢复后继续从上次成功发送的记录后开始消费;
-
当出现异常时,回退 offset 并等待后重试。打印日志,触发告警,人为介入。若为网络原因,则自行恢复;
-
优雅关闭,关闭前处理完当前内存中的消息再关闭。
线上实践效果
(1) 单队列可支撑的吞吐量
目前单队列(队列对应的是一个单分片的 topic)在延迟转发服务实例配置为 2 核 4G 的情况下进行压测,结果如表 4-1 所示(数据仅供参考,未进行参数调优):
| 消息大小 | 语义 | 最大吞吐 |
| 10字节 | 至少一次 | 17w/s |
| 10字节 | 有且仅有一次 | 3w/s |
| 2kb | 至少一次 | 3.1w/s |
| 2kb | 有且仅有一次 | 1.9w/s |
表 4-1 吞吐量压测结果
Redis 实现
监听过期 key
基于监听过期 key 的方式来实现延迟队列是我查到的第一个方案,为了弄懂这个方案实现的细节,我还特地去扒了扒官网,还真有所收获
1、Redis 发布订阅模式
一谈到发布订阅模式,其实一想到的就是 MQ,只不过 Redis 也实现了一套,并且跟 MQ 贼像,如图:
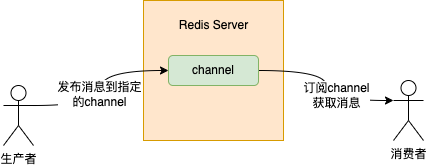
图中的 channel 的概念跟 MQ 中的 topic 的概念差不多,你可以把 channel 理解成 MQ 中的 topic。
生产者在消息发送时需要到指定发送到哪个 channel 上,消费者订阅这个 channel 就能获取到消息。
2、keyspace notifications
在 Redis 中,有很多默认的 channel,只不过向这些 channel 发送消息的生产者不是我们写的代码,而是 Redis 本身。当消费者监听这些 channel 时,就可以感知到 Redis 中数据的变化。
这个功能 Redis 官方称为 keyspace notifications,字面意思就是键空间通知。
这些默认的 channel 被分为两类:
- 以
__keyspace@<db>__:为前缀,后面跟的是 key 的名称,表示监听跟这个 key 有关的事件。
举个例子,现在有个消费者监听了__keyspace@0__:sanyou这个 channel,sanyou 就是 Redis 中的一个普通 key,那么当 sanyou 这个 key 被删除或者发生了其它事件,那么消费者就会收到 sanyou 这个 key 删除或者其它事件的消息 - 以
__keyevent@<db>__:为前缀,后面跟的是消息事件类型,表示监听某个事件
同样举个例子,现在有个消费者监听了__keyevent@0__:expired这个 channel,代表了监听 key 的过期事件。那么当某个 Redis 的 key 过期了(expired),那么消费者就能收到这个 key 过期的消息。如果把 expired 换成 del,那么监听的就是删除事件。具体支持哪些事件,可从官网查。
上述 db 是指具体的数据库,Redis 不是默认分为 16 个库么,序号从 0-15,所以 db 就是 0 到 15 的数字,示例中的 0 就是指 0 对应的数据库。
3、延迟队列实现原理
通过对上面的两个概念了解之后,应该就对监听过期key的实现原理一目了然了,其实就是当这个key过期之后,Redis会发布一个key过期的事件到 __keyevent@<db>__:expired 这个 channel,只要我们的服务监听这个 channel,那么就能知道过期的 Key,从而就算实现了延迟队列功能。
所以这种方式实现延迟队列就只需要两步:
- 发送延迟任务,key 是延迟消息本身,过期时间就是延迟时间
- 监听
__keyevent@<db>__:expired这个 channel,处理延迟任务
4、demo
好了,基本概念和核心原理都说完了之后,又到了 show me the code 环节。
好巧不巧,Spring已经实现了监听 __keyevent@*__:expired 这个 channel 这个功能,__keyevent@*__:expired 中的 * 代表通配符的意思,监听所有的数据库。
所以 demo 写起来就很简单了,只需 3 步即可
引入 pom
`<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>`
配置类
`@Configuration
public class RedisConfiguration {
@Bean
public RedisMessageListenerContainer redisMessageListenerContainer(RedisConnectionFactory connectionFactory) {
RedisMessageListenerContainer redisMessageListenerContainer = new RedisMessageListenerContainer();
redisMessageListenerContainer.setConnectionFactory(connectionFactory);
return redisMessageListenerContainer;
}
@Bean
public KeyExpirationEventMessageListener redisKeyExpirationListener(RedisMessageListenerContainer redisMessageListenerContainer) {
return new KeyExpirationEventMessageListener(redisMessageListenerContainer);
}
}`
KeyExpirationEventMessageListener实现了对 __keyevent@*__:expired channel 的监听
当 KeyExpirationEventMessageListener 收到 Redis 发布的过期 Key 的消息的时候,会发布 RedisKeyExpiredEvent 事件
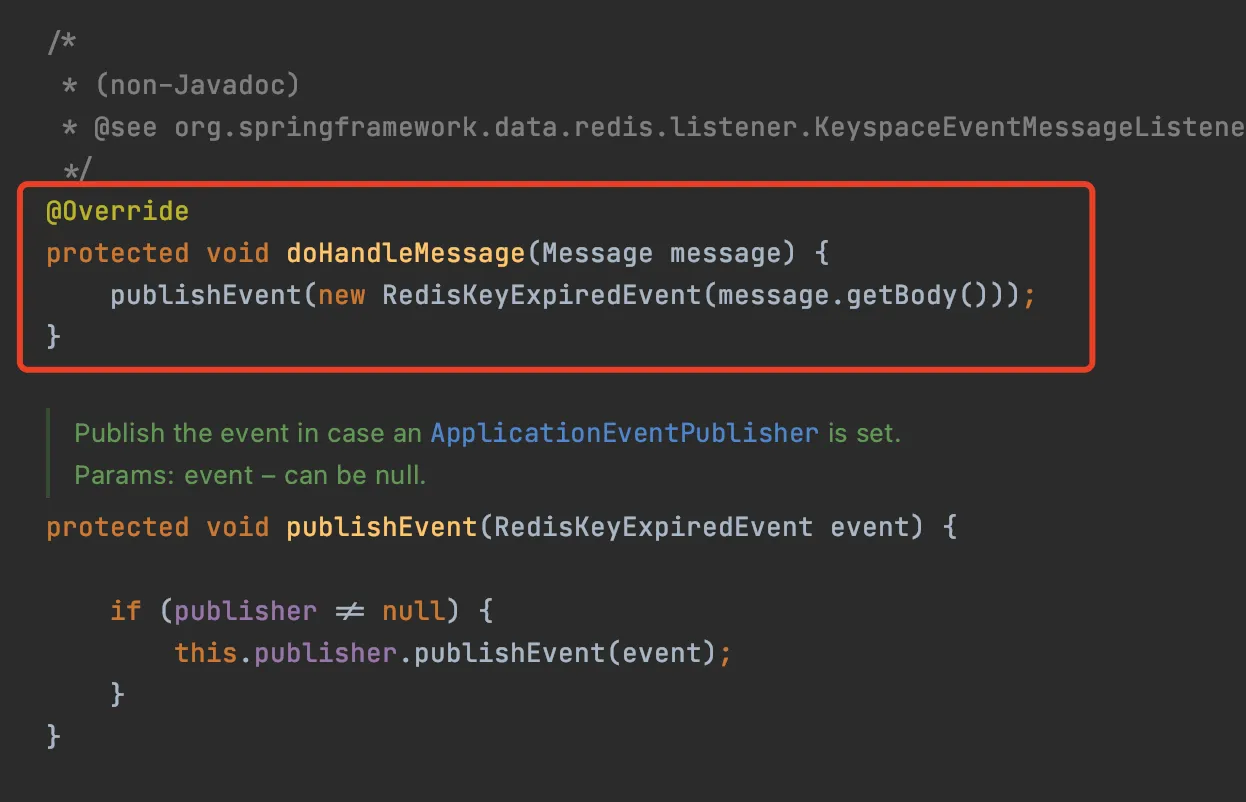
所以我们只需要监听 RedisKeyExpiredEvent 事件就可以拿到过期消息的 Key,也就是延迟消息。
对 RedisKeyExpiredEvent 事件的监听实现 MyRedisKeyExpiredEventListener
`@Component
public class MyRedisKeyExpiredEventListener implements ApplicationListener<RedisKeyExpiredEvent> {
@Override
public void onApplicationEvent(RedisKeyExpiredEvent event) {
byte[] body = event.getSource();
System.out.println("获取到延迟消息:" + new String(body));
}
}`
整个工程目录也简单

代码写好,启动应用
之后我直接通过 Redis 命令设置消息,就没通过代码发送消息了,消息的 key 为 sanyou,值为 task,值不重要,过期时间为 5s
set sanyou task
expire sanyou 5如果上面都理论都正确,不出意外的话,5s后MyRedisKeyExpiredEventListener应该可以监听到sanyou这个key过期的消息,也就相当于拿到了延迟任务,控制台会打印出 获取到延迟消息:sanyou。
于是我满怀希望,静静地等待了 5s。。
5、4、3、2、1,时间一到,我查看控制台,但是控制台并没有按照预期打印出上面那句话。
为什么会没打印出?难道是代码写错了?正当我准备检查代码的时候,官网的一段话道出了真实原因。
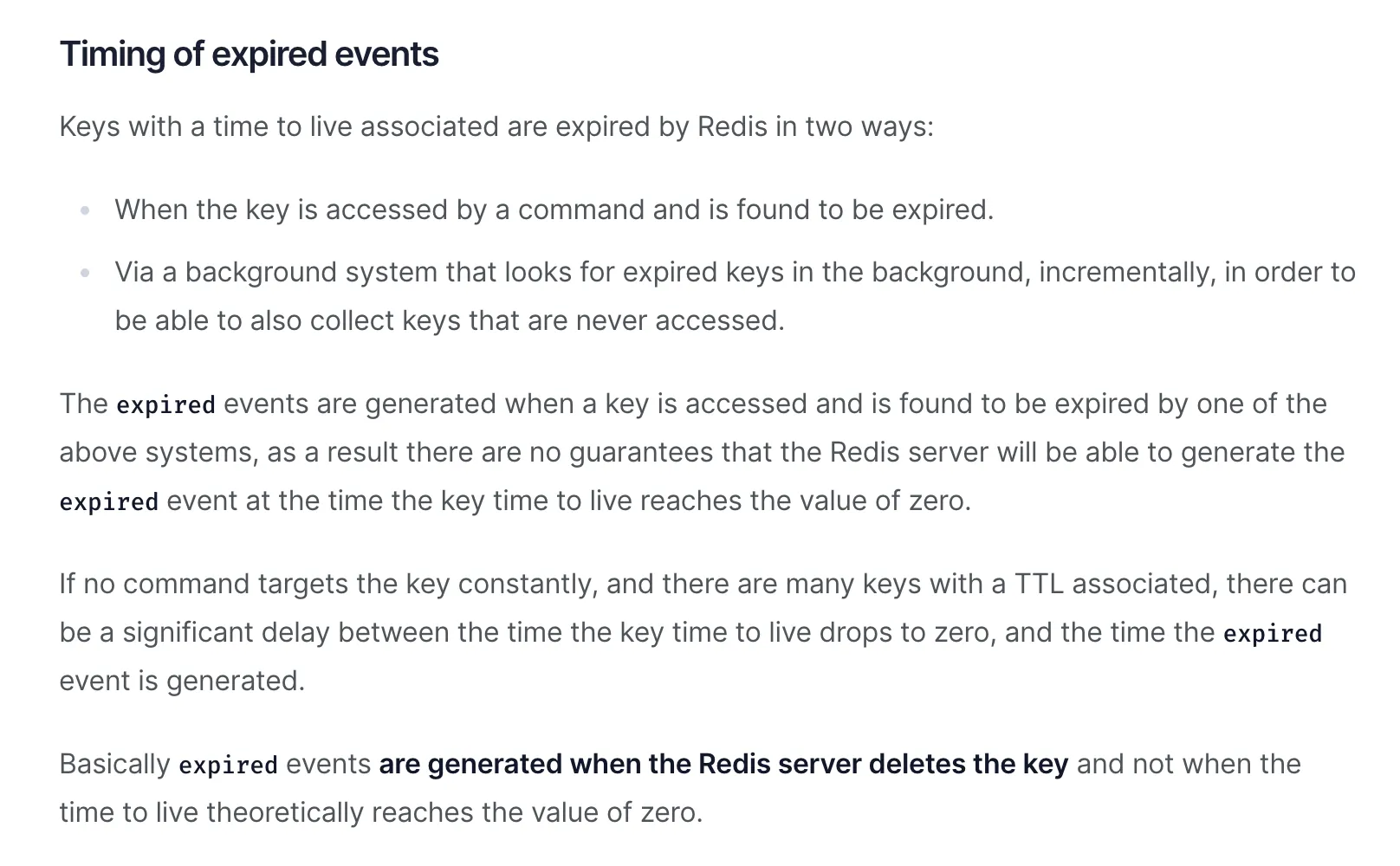
我给大家翻译一下上面这段话讲的内容。
上面这段话主要讨论的是 key 过期事件的时效性问题,首先提到了 Redis 过期 key 的两种清除策略,就是面试八股文常背的两种:
- 惰性清除。当这个 key 过期之后,访问时,这个 Key 才会被清除
- 定时清除。后台会定期检查一部分 key,如果有 key 过期了,就会被清除
再后面那段话是核心,意思是说,key 的过期事件发布时机并不是当这个 key 的过期时间到了之后就发布,而是这个 key 在 Redis 中被清理之后,也就是真正被删除之后才会发布。
到这我终于明白了,上面的例子中即使我设置了 5s 的过期时间,但是当 5s 过去之后,只要两种清除策略都不满足,没人访问 sanyou 这个 key,后台的定时清理的任务也没扫描到 sanyou 这个 key,那么就不会发布 key 过期的事件,自然而然也就监听不到了。
至于后台的定时清理的任务什么时候能扫到,这个没有固定时间,可能一到过期时间就被扫到,也可能等一定时间才会被扫到,这就可能会造成了客户端从发布到监听到的消息时间差会大于等于过期时间,从而造成一定时间消息的延迟,这就着实有点坑了。。
5、坑
除了上面测试 demo 的时候遇到的坑之外,在我深入研究之后,还发现了一些更离谱的坑。
丢消息太频繁
Redis 的丢消息跟 MQ 不一样,因为 MQ 都会有消息的持久化机制,可能只有当机器宕机了,才会丢点消息,但是 Redis 丢消息就很离谱,比如说你的服务在重启的时候就消息会丢消息。
Redis 实现的发布订阅模式,消息是没有持久化机制,当消息发布到某个 channel 之后,如果没有客户端订阅这个 channel,那么这个消息就丢了,并不会像 MQ 一样进行持久化,等有消费者订阅的时候再给消费者消费。
所以说,假设服务重启期间,某个生产者或者是 Redis 本身发布了一条消息到某个 channel,由于服务重启,没有监听这个 channel,那么这个消息自然就丢了。
消息消费只有广播模式
Redis 的发布订阅模式消息消费只有广播模式一种。
所谓的广播模式就是多个消费者订阅同一个 channel,那么每个消费者都能消费到发布到这个 channel 的所有消息。
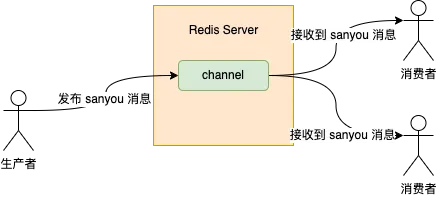
如图,生产者发布了一条消息,内容为 sanyou,那么两个消费者都可以同时收到 sanyou 这条消息。
所以,如果通过监听 channel 来获取延迟任务,那么一旦服务实例有多个的话,还得保证消息不能重复处理,额外地增加了代码开发量。
接收到所有 key 的某个事件
这个不属于 Redis 发布订阅模式的问题,而是 Redis 本身事件通知的问题。
当消费者监听了以 __keyevent@<db>__: 开头的消息,那么会导致所有的 key 发生了事件都会被通知给消费者。
举个例子,某个消费者监听了 __keyevent@*__:expired 这个 channel,那么只要 key 过期了,不管这个 key 是张三还会李四,消费者都能收到。
所以如果你只想消费某一类消息的 key,那么还得自行加一些标记,比如消息的 key 加个前缀,消费的时候判断一下带前缀的 key 就是需要消费的任务。
所以,综上能够得出一个非常重要的结论,那就是监听 Redis 过期 Key 这种方式实现延迟队列, 不稳定,坑贼多!
那有没有比较靠谱的延迟队列的实现方案呢?这就不得不提到我研究的第二种方案了。
Redisson 实现延迟队列
Redisson 他是 Redis 的儿子(Redis son),基于 Redis 实现了非常多的功能,其中最常使用的就是 Redis 分布式锁的实现,但是除了实现 Redis 分布式锁之外,它还实现了延迟队列的功能。
先来个 demo,后面再来说说这种实现的原理。
1、demo
引入 pom
`<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.1</version>
</dependency>`
封装了一个 RedissonDelayQueue 类
`@Component
@Slf4j
public class RedissonDelayQueue {
private RedissonClient redissonClient;
private RDelayedQueue<String> delayQueue;
private RBlockingQueue<String> blockingQueue;
@PostConstruct
public void init() {
initDelayQueue();
startDelayQueueConsumer();
}
private void initDelayQueue() {
Config config = new Config();
SingleServerConfig serverConfig = config.useSingleServer();
serverConfig.setAddress("redis://localhost:6379");
redissonClient = Redisson.create(config);
blockingQueue = redissonClient.getBlockingQueue("SANYOU");
delayQueue = redissonClient.getDelayedQueue(blockingQueue);
}
private void startDelayQueueConsumer() {
new Thread(() -> {
while (true) {
try {
String task = blockingQueue.take();
log.info("接收到延迟任务:{}", task);
} catch (Exception e) {
e.printStackTrace();
}
}
}, "SANYOU-Consumer").start();
}
public void offerTask(String task, long seconds) {
log.info("添加延迟任务:{} 延迟时间:{}s", task, seconds);
delayQueue.offer(task, seconds, TimeUnit.SECONDS);
}
}`
这个类在创建的时候会去初始化延迟队列,创建一个 RedissonClient 对象,之后通过 RedissonClient 对象获取到 RDelayedQueue 和 RBlockingQueue 对象,传入的队列名字叫 SANYOU,这个名字无所谓。
当延迟队列创建之后,会开启一个延迟任务的消费线程,这个线程会一直从 RBlockingQueue 中通过 take 方法阻塞获取延迟任务。
添加任务的时候是通过 RDelayedQueue 的 offer 方法添加的。
controller 类,通过接口添加任务,延迟时间为 5s
`@RestController
public class RedissonDelayQueueController {
@Resource
private RedissonDelayQueue redissonDelayQueue;
@GetMapping("/add")
public void addTask(@RequestParam("task") String task) {
redissonDelayQueue.offerTask(task, 5);
}
}`
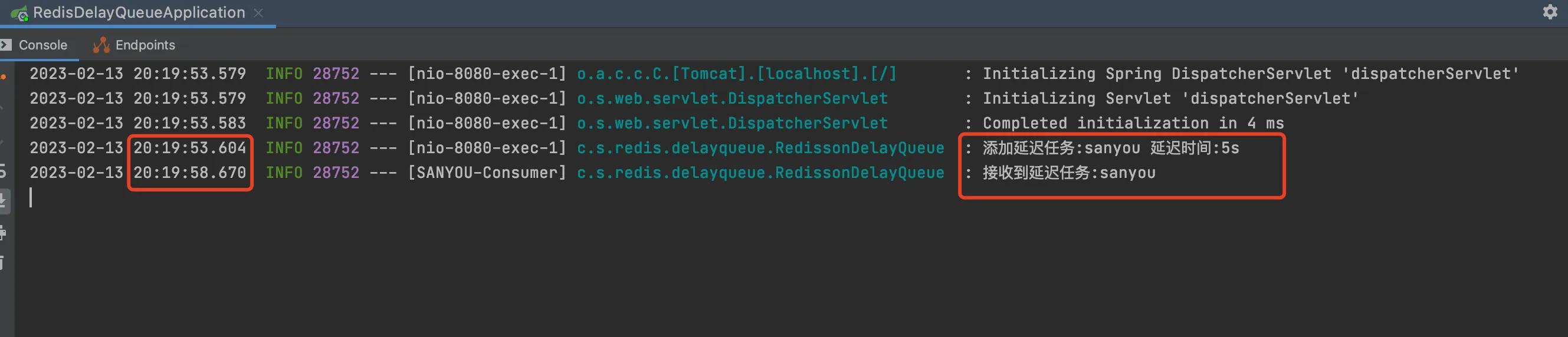
启动项目,在浏览器输入如下连接,添加任务
http://localhost:8080/add?task=sanyou
静静等待 5s,成功获取到任务。
2、实现原理
如下图就是上面 demo 中,一个延迟队列会在 Redis 内部使用到的 channel 和数据类型
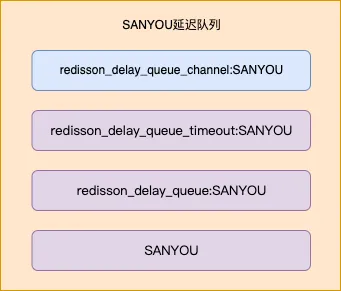
SANYOU 前面的前缀都是固定的,Redisson 创建的时候会拼上前缀。
redisson_delay_queue_timeout:SANYOU,sorted set 数据类型,存放所有延迟任务,按照延迟任务的到期时间戳(提交任务时的时间戳 + 延迟时间)来排序的,所以列表的最前面的第一个元素就是整个延迟队列中最早要被执行的任务,这个概念很重要redisson_delay_queue:SANYOU,list 数据类型,也是存放所有的任务,但是研究下来发现好像没什么用。。SANYOU,list 数据类型,被称为目标队列,这个里面存放的任务都是已经到了延迟时间的,可以被消费者获取的任务,所以上面 demo 中的 RBlockingQueue 的 take 方法是从这个目标队列中获取到任务的redisson_delay_queue_channel:SANYOU,是一个 channel,用来通知客户端开启一个延迟任务
有了这些概念之后,再来看看整体的运行原理图
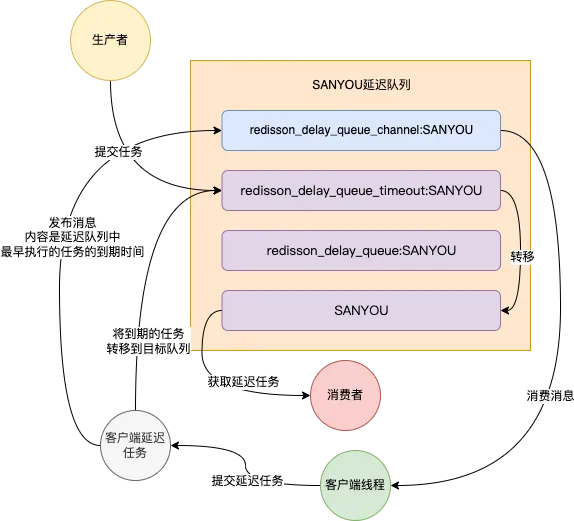
- 生产者在提交任务的时候将任务放到
redisson_delay_queue_timeout:SANYOU中,分数就是提交任务的时间戳+延迟时间,就是延迟任务的到期时间戳 - 客户端会有一个延迟任务,为了区分,后面我都说是客户端延迟任务。这个延迟任务会向 Redis Server 发送一段 lua 脚本,Redis 执行 lua 脚本中的命令,并且是原子性的
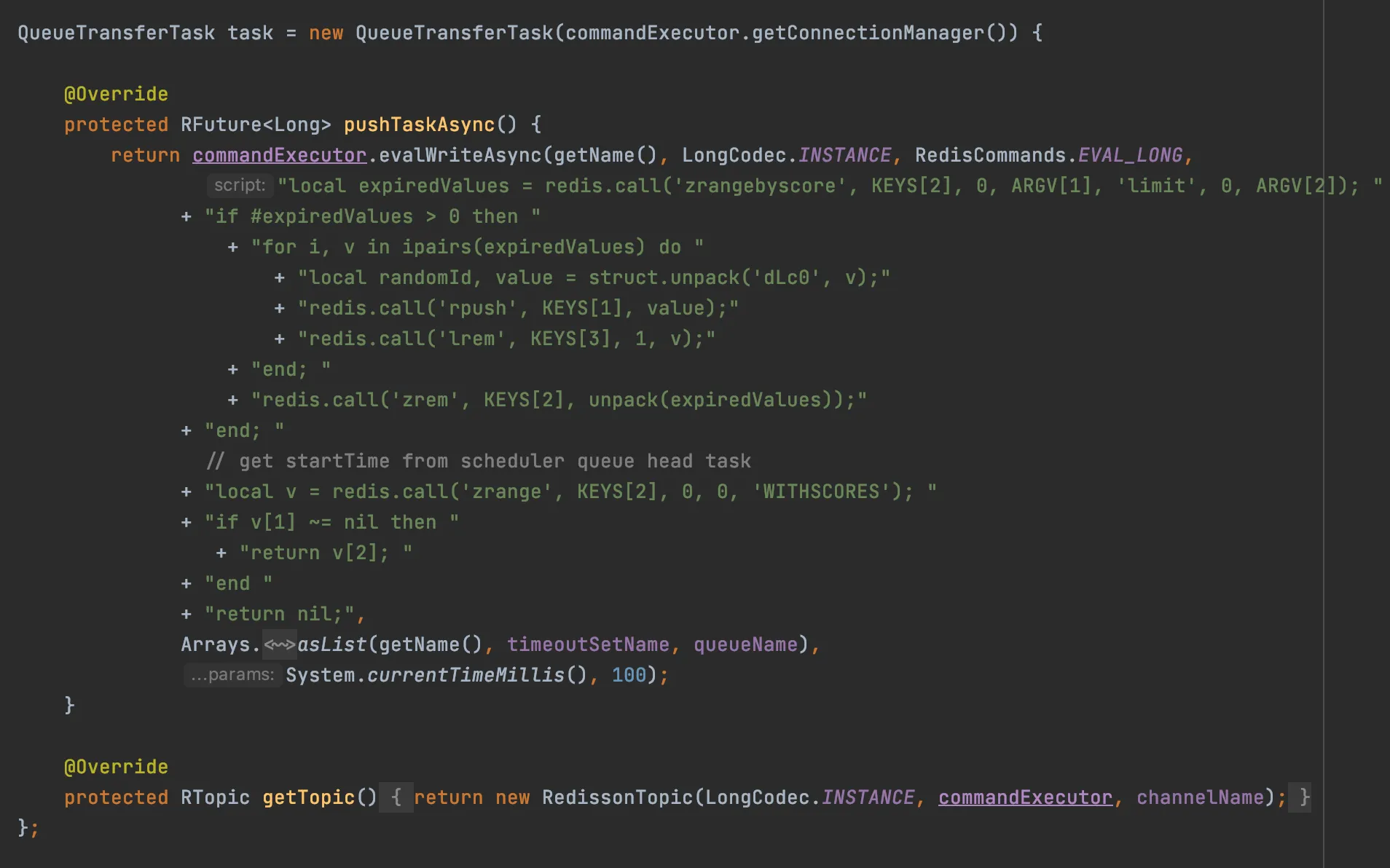
这段 lua 脚本主要干了两件事:
- 将到了延迟时间的任务从
redisson_delay_queue_timeout:SANYOU中移除,存到SANYOU这个目标队列 - 获取到
redisson_delay_queue_timeout:SANYOU中目前最早到过期时间的延迟任务的到期时间戳,然后发布到redisson_delay_queue_channel:SANYOU这个 channel中
当客户端监听到redisson_delay_queue_channel:SANYOU这个 channel 的消息时,会再次提交一个客户端延迟任务,延迟时间就是消息(最早到过期时间的延迟任务的到期时间戳)- 当前时间戳,这个时间其实也就是redisson_delay_queue_channel:SANYOU中最早到过期时间的任务还剩余的延迟时间。
此处可以等待 10s,好好想想。。
这样,一旦时间来到了上面说的最早到过期时间任务的到期时间戳,redisson_delay_queue_timeout:SANYOU 中上面说的最早到过期时间的任务已经到期了,客户端的延迟任务也同时到期,于是开始执行 lua 脚本操作,及时将到了延迟时间的任务放到目标队列中。然后再次发布剩余的延迟任务中最早到期的任务到期时间戳到 channe 中,如此循环往复,一直运行下去,保证 redisson_delay_queue_timeout:SANYOU 中到期的数据能及时放到目标队列中。
所以,上述说了一大堆的主要的作用就是保证到了延迟时间的任务能够及时被放到目标队列。
这里再补充两个特殊情况,图中没有画出:
第一个就是如果 redisson_delay_queue_timeout:SANYOU 是新添加的任务(队列之前有或者没有任务)是队列中最早需要被执行的,也会发布消息到 channel,之后就按时上面说的流程走了。
添加任务代码如下,也是通过 lua 脚本来的
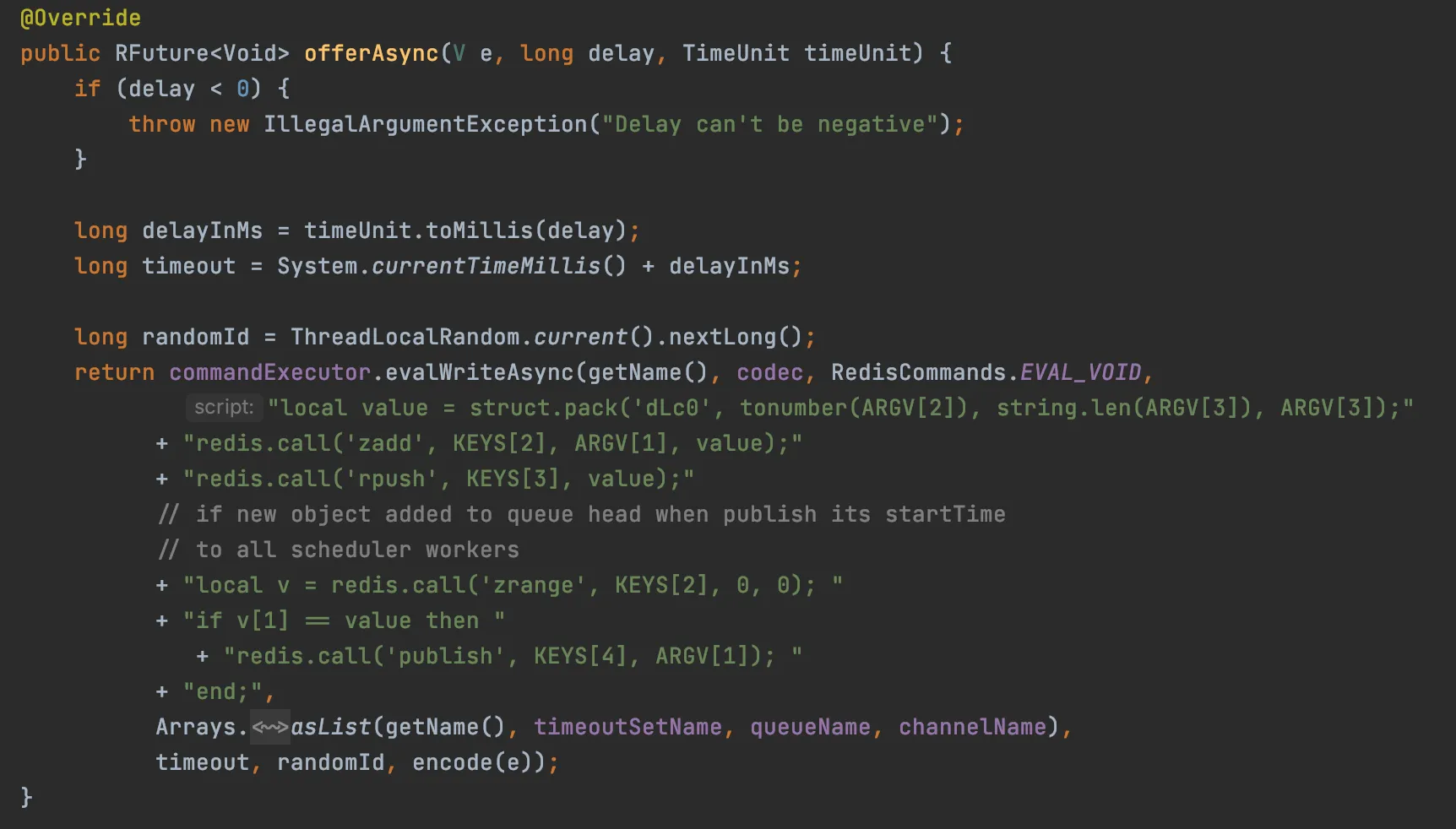
第二种特殊情况就是项目启动的时候会执行一次客户端延迟任务。项目在重启时,由于没有客户端延迟任务的执行,可能会出现 redisson_delay_queue_timeout:SANYOU 队列中有到期但是没有被放到目标队列的可能,重启就执行一次就是为了保证到期的数据能被及时放到目标队列中。
3、与第一种方案比较
现在来比较一下第一种方案和 Redisson 的这种方案,看看有没有第一种方案的那些坑。
第一个任务延迟的问题,Redisson 方案理论上是没有延迟的,但是当消息数量增加,消费者消费缓慢这个情况下可能会导致延迟任务消费的延迟。
第二个丢消息的问题,Redisson 方案很大程度上减轻了丢消息的可能性,因为所有的任务都是存在 list 和 sorted set 两种数据类型中,Redis 有持久化机制,就算 Redis 宕机了,也就可能会丢一点点数据。
第三个广播消费任务的问题,这个是不会出现的,因为每个客户端都是从同一个目标队列中获取任务的。
第四个问题是 Redis 内部 channel 发布事件的问题,跟这种方案不沾边,就更不可能存在了。
所以,通过上面的对比可以看出,Redisson 这种实现方案就显得更加的靠谱了。