不要把每一次对话都当作一张白纸,智能体可以存储关系、回忆上下文,并在相互关联的信息之间进行实时推理。这也是为什么知识图谱在智能体开发者中如此受欢迎。
而且不只是智能体在使用。知识图谱还支撑着当今生产环境中一些最苛刻、最复杂的系统:
这些本质上都是 图问题 ,核心在于理解事物之间是如何相互关联的。
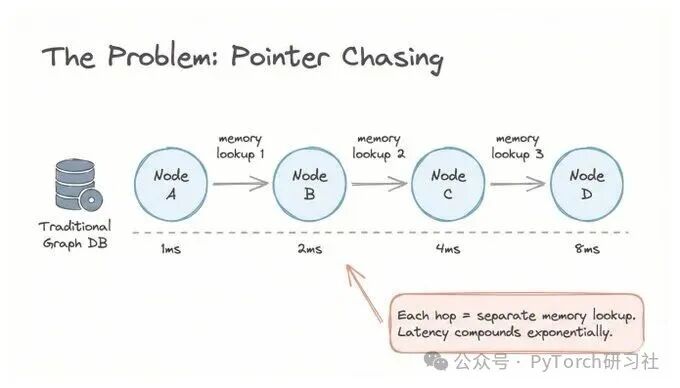
以 Neo4j 为代表的传统的图数据库将关系存储为指针。要遍历这些关系,你需要一次追踪一个指针:
- 从节点 A 开始
- 沿着一条连接到达节点 B
- 读取 B 的连接关系
- 跳转到节点 C
- 不断重复
每一次“跳转”都需要一次单独的内存访问。探索的连接越多,速度就越慢。
对于简单查询来说,这种方式没有问题。但当你的智能体需要在 实时 场景下,对成千上万个实体进行 多跳推理 时,每一毫秒的延迟都会不断累积,最终成为瓶颈。
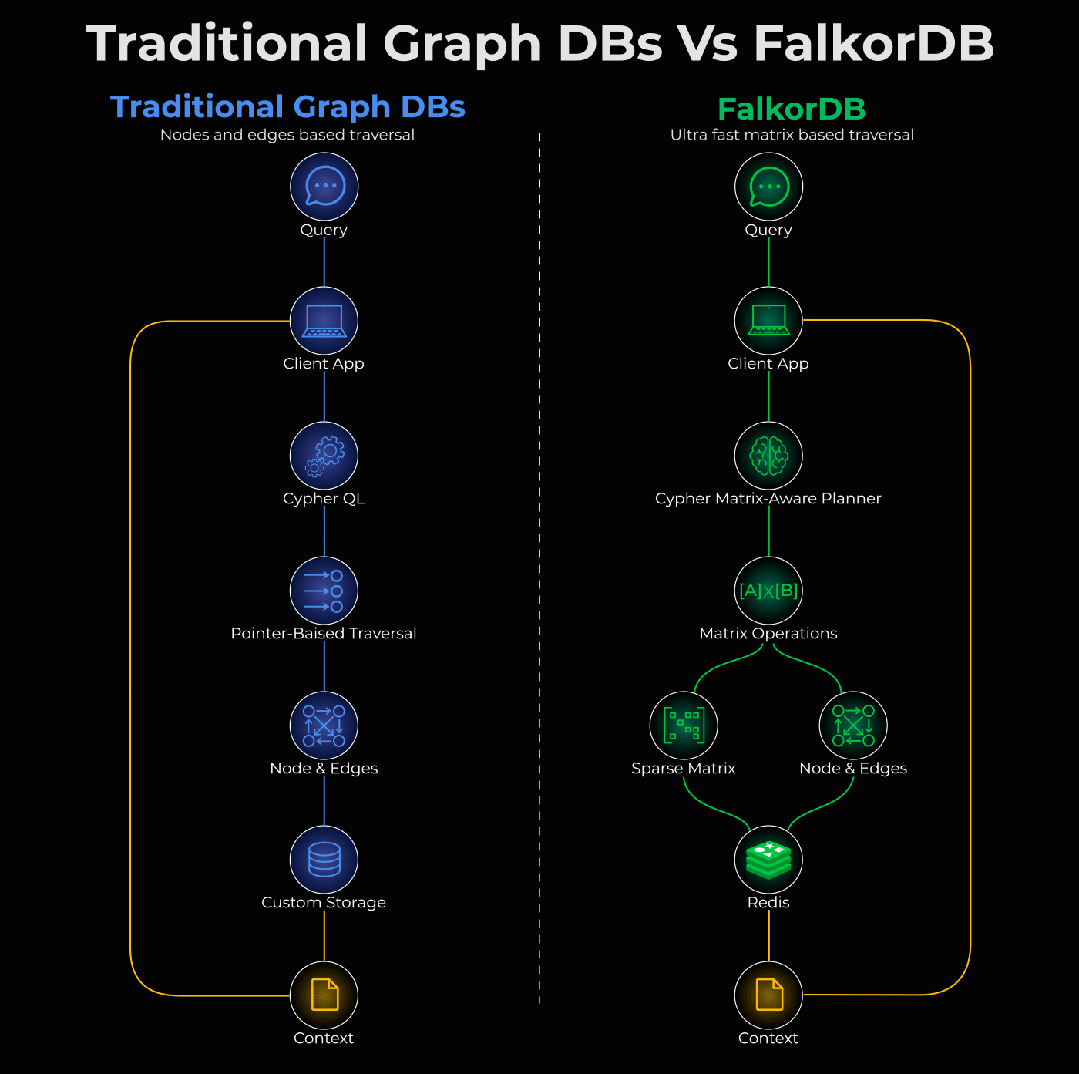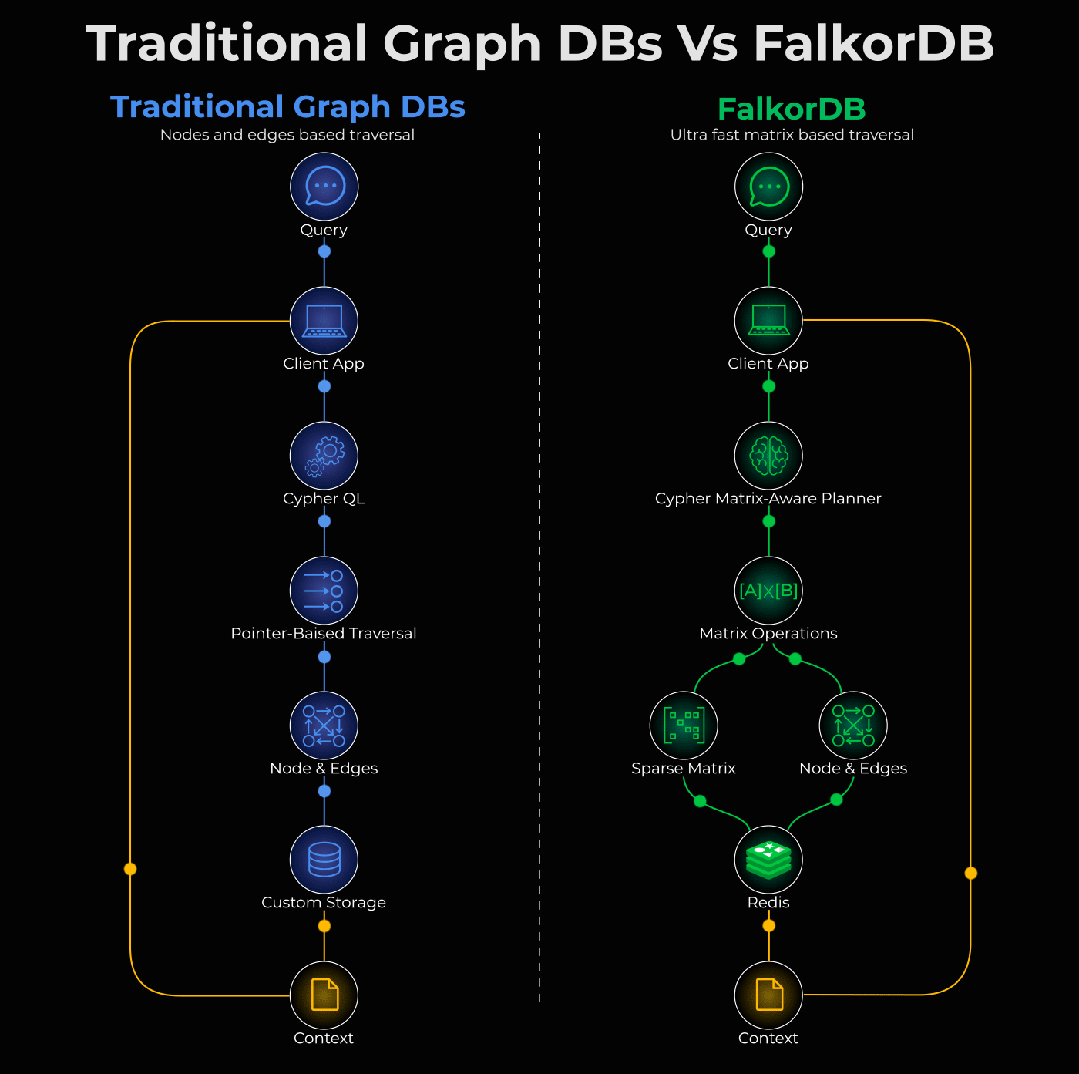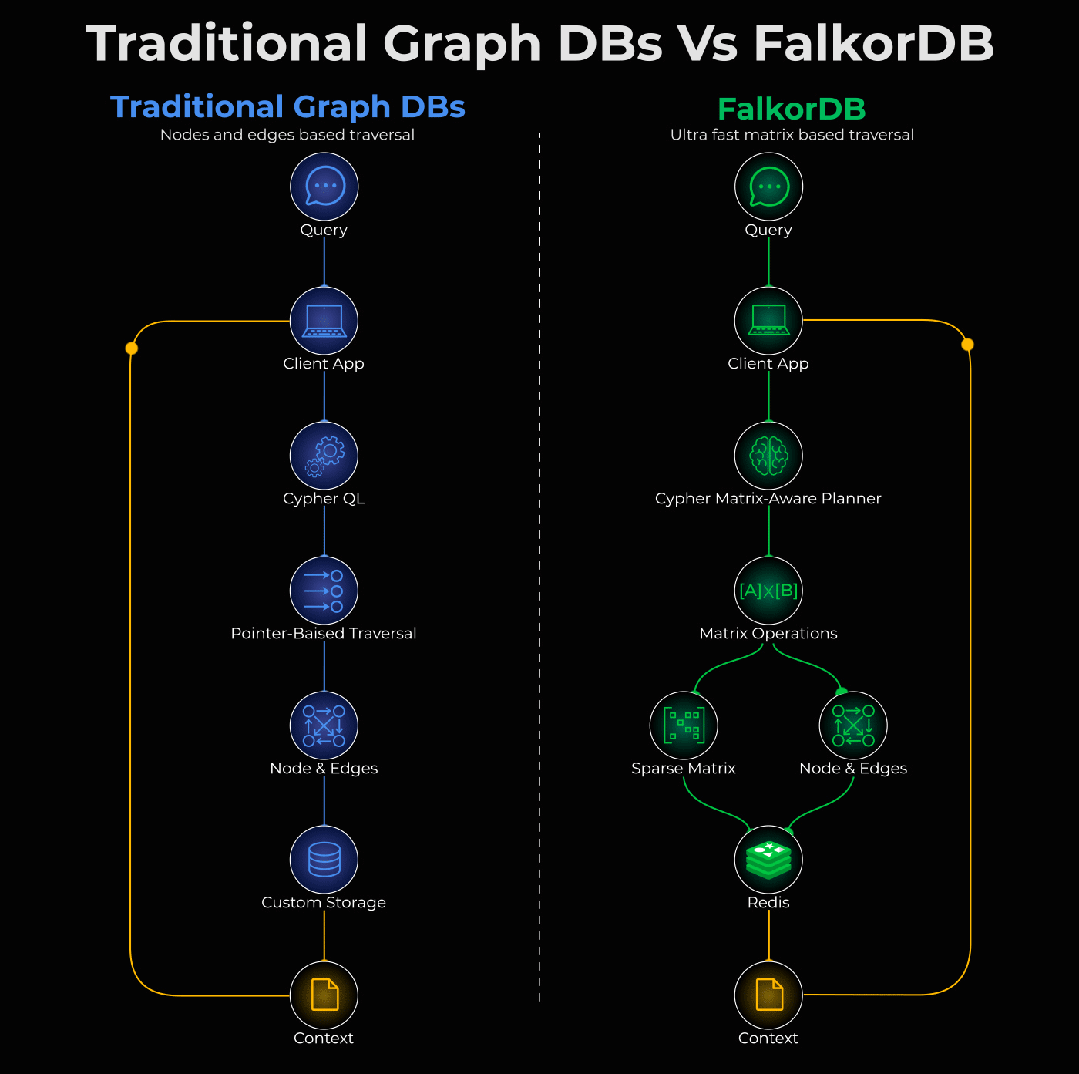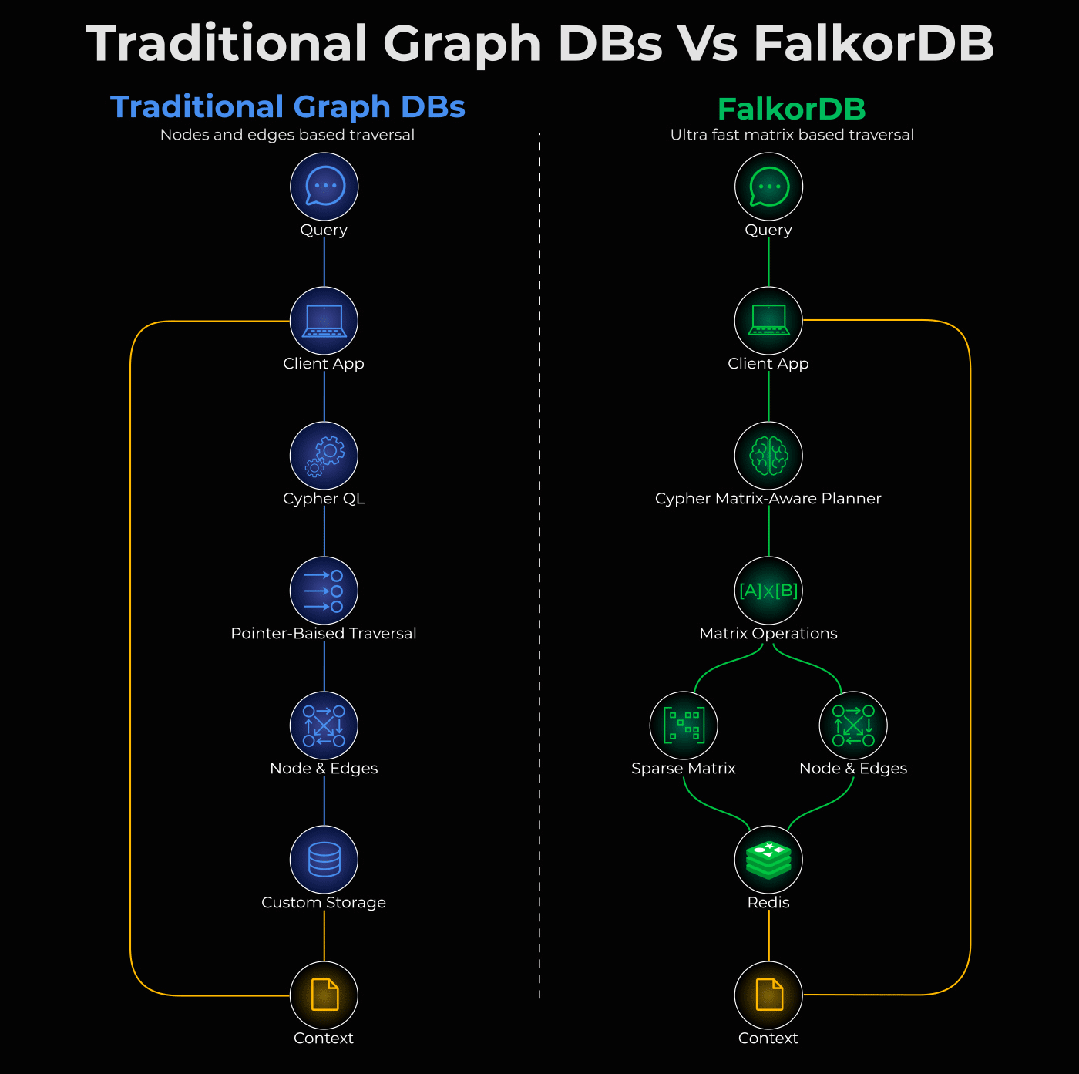
FalkorDB 的速度比 Neo4j 快 496 倍 。
它是一个开源图数据库,将整个图表示为一个 稀疏矩阵 。不再通过追踪指针来遍历关系,而是把图遍历转换为 矩阵运算 ,并且可以 并行执行 。
从实际角度来看,这意味着:
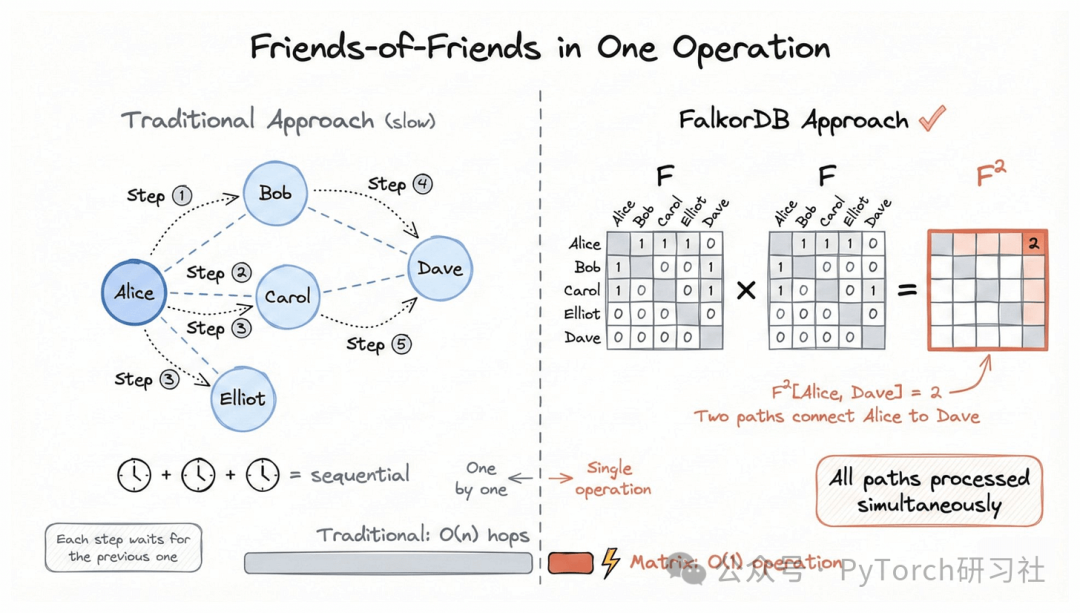
假设你想在校园BBS中查找朋友的朋友:也就是说, 和 Alice 的朋友相连的人都有谁?
传统做法:
- 从 Alice 开始,先找到她的朋友(Bob、Carol、Elliot)。
- 然后对每一个朋友,再去查找他们各自的朋友。
- 最后把结果合并起来。
每一步都是 顺序执行 的。
FalkorDB 的做法:
把整个社交图表示成一个矩阵 F ,其中:
- 如果第 i 个人和第 j 个人是朋友
- 那么矩阵位置 F[i, j] = 1
这样一来,查找“朋友的朋友”就变成了一次 矩阵乘法 :
F × F = F²
结果中,如果 F²[Alice, Dave] = 2 ,就表示:
Alice 和 Dave 之间存在两条不同的连接路径 ,即使他们并不是直接好友。
换句话说:不再一条一条地追踪关系,而是由 CPU 同时并行处理所有路径。
来看一下这个效果:
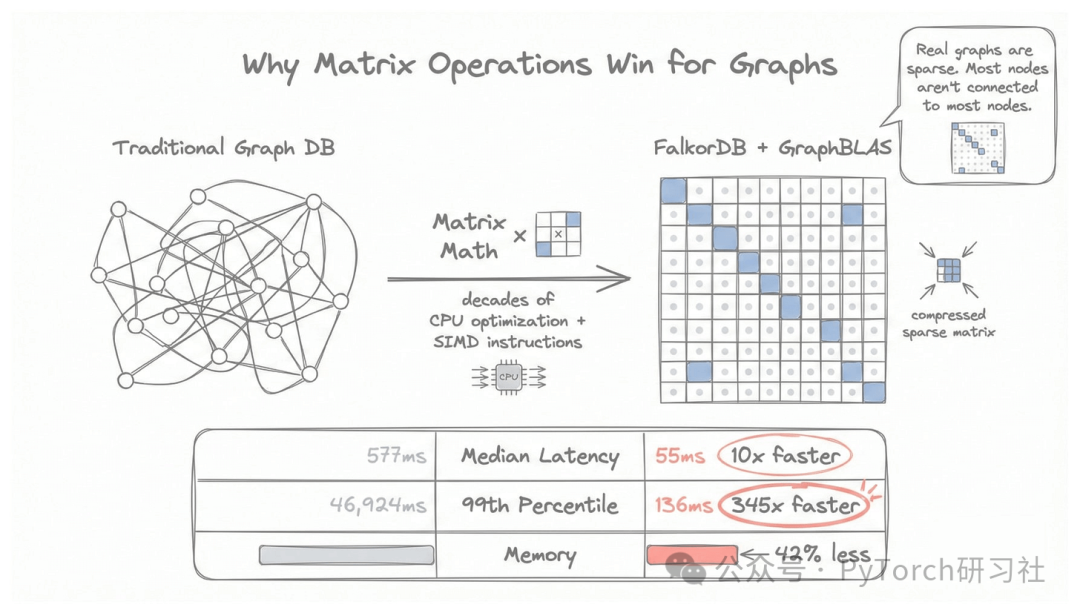
为什么它这么快?
矩阵运算已经被优化了几十年。现代 CPU 针对这类计算提供了专门的 SIMD 指令 ,正是为此而生的。
FalkorDB 在底层使用的是 GraphBLAS —— 这套数学体系同样被用于高性能科学计算领域。
此外,现实世界中的图大多是 稀疏的 :
- 大多数人并不关注大多数人
- 大多数商品也并不和大多数商品相关
FalkorDB 使用 压缩稀疏矩阵(Compressed Sparse Matrix) 格式,只存储真实存在的关系。
因此,性能差距非常明显:
- 中位延迟:55ms vs 577ms(快 10 倍)
- 99 分位延迟:136ms vs 46,924ms(快 345 倍)
- 内存使用:减少 42%
即使在 极端高负载 下,FalkorDB 依然能将响应时间稳定控制在 140ms 以内 。
实战
我们可以用 Docker 在本地启动一个FalkorDB服务:
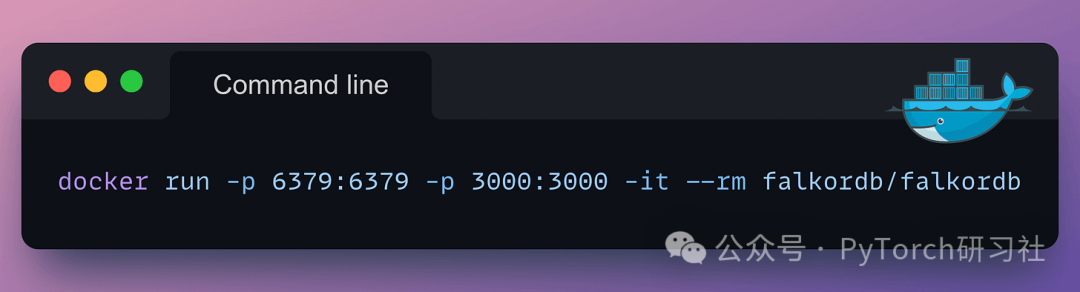
数据库运行在 6379 端口,打开浏览器输入 localhost:3000 可以进入FalkorDB Web UI。
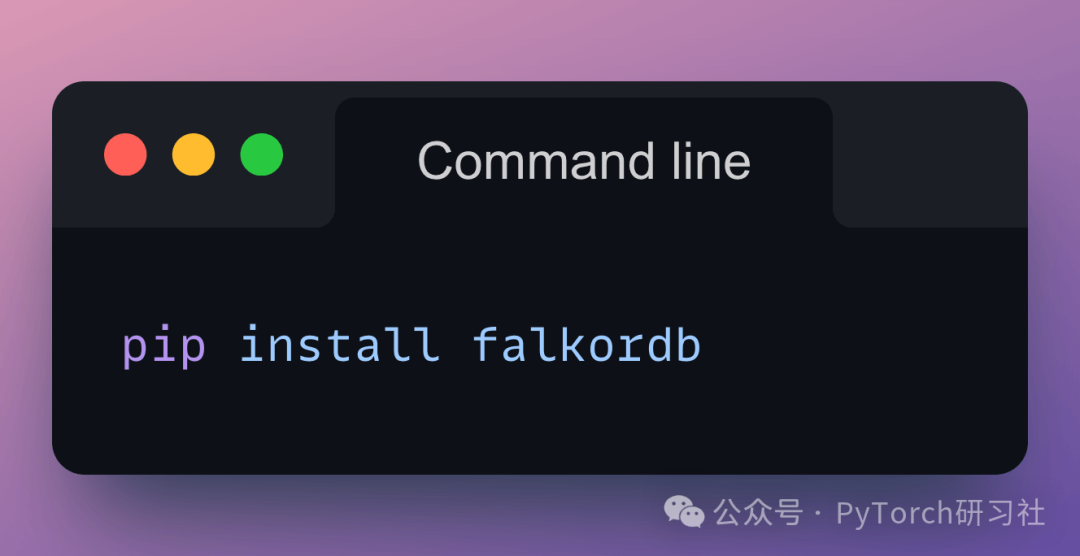
安装 Python 客户端:
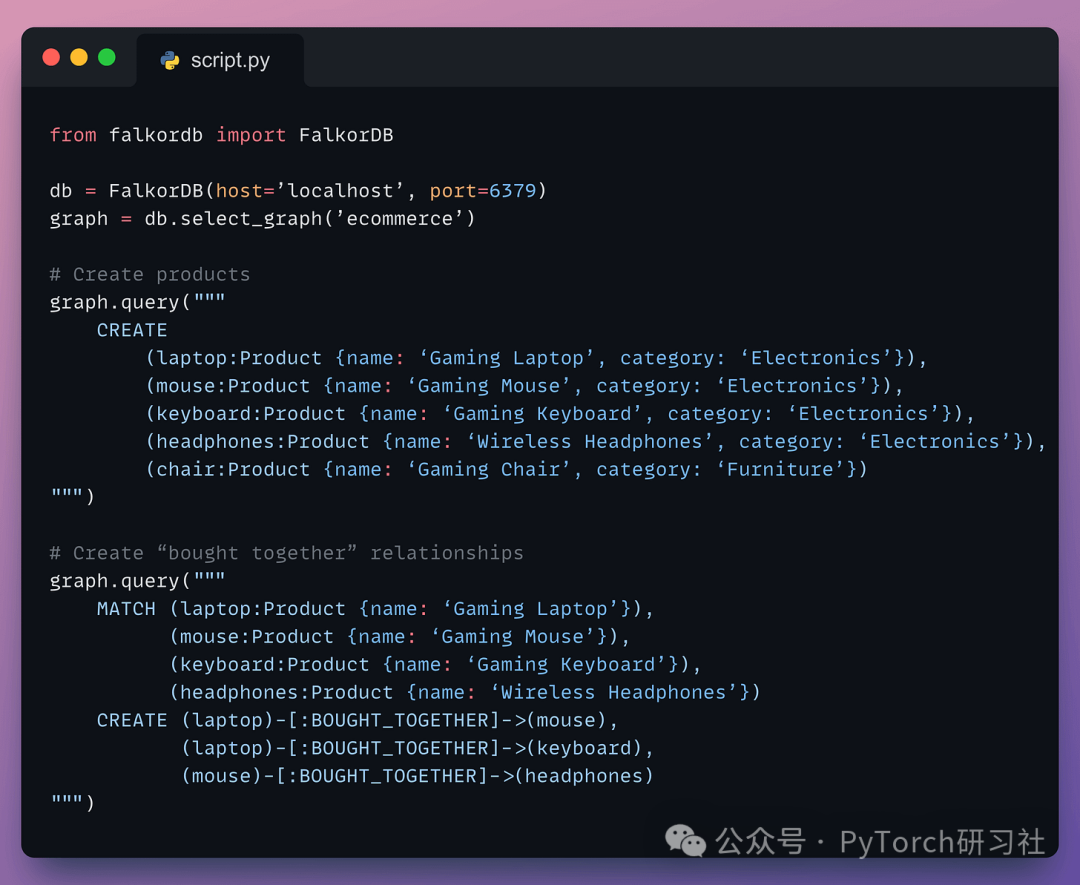
现在创建一个电商网站数据库:
找到经常购买游戏本的人:
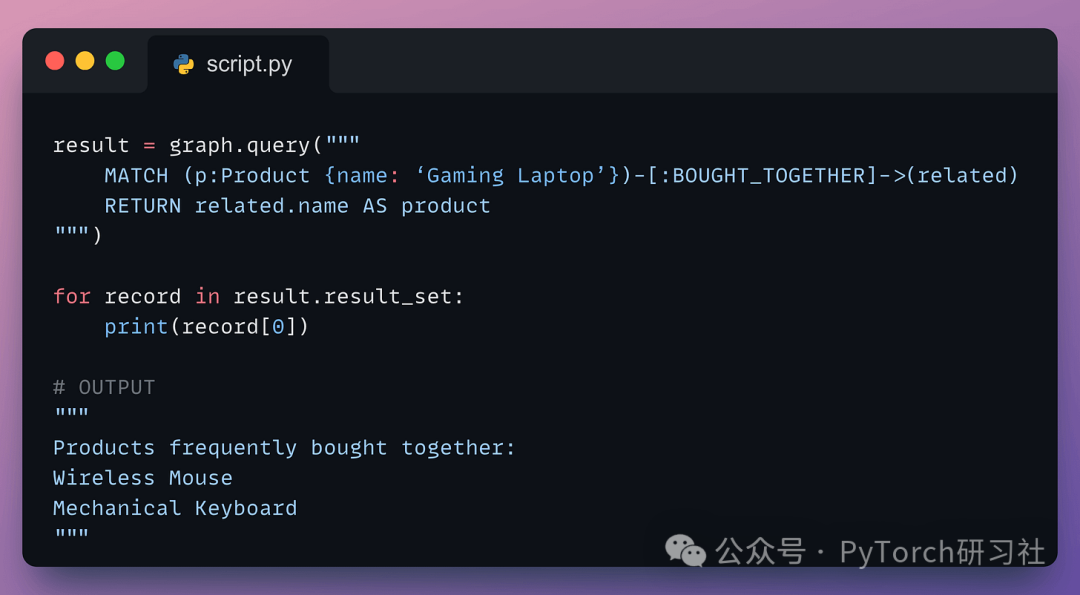
查询语言是 OpenCypher ,在进行关系型查询时,它的可读性和直观性都比 SQL 更强。
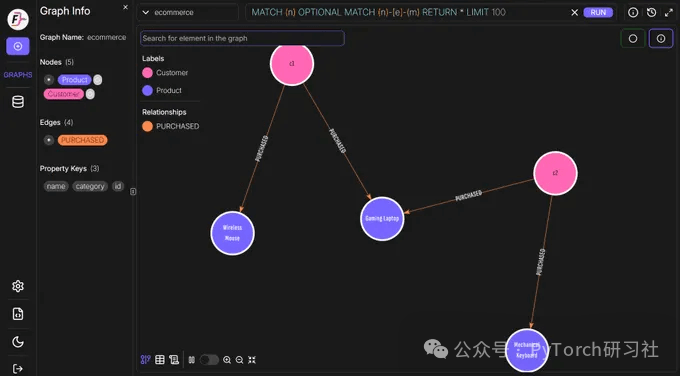
我们可以从图中验证查询结果的 正确性 。
OpenCypher 覆盖了基础能力,但如果需要更专业的逻辑呢?
比如,你可能需要用于 推荐系统的自定义相似度评分 ,或者用于 反欺诈的规则 ,以反映你公司独特的风险模式。
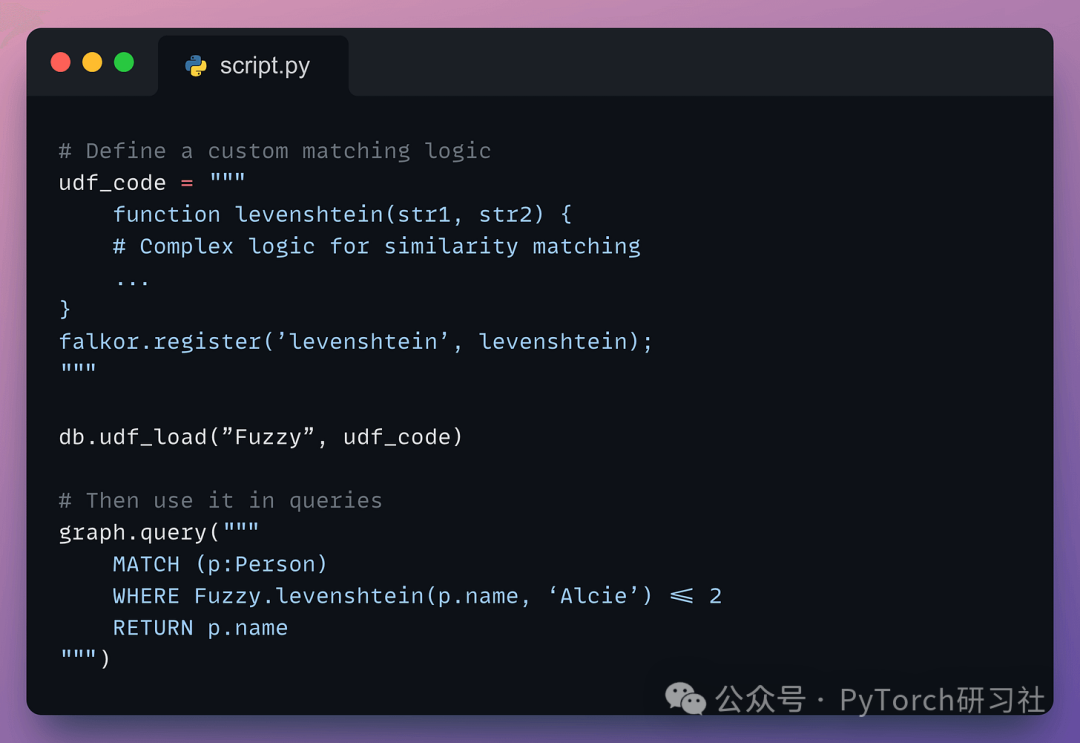
用户自定义函数(UDF) 允许我们编写 JavaScript 函数 ,并且可以直接访问:
- 节点的邻居
- 节点属性
- 路径信息
FalkorDB FLEX 为常见任务提供了 预置的 UDF 。
示例:用户搜索中的模糊匹配
假设有人把 “Alice” 错输成了 “Alcie” 。
如果不使用 FLEX,你就需要自己编写一套自定义的匹配逻辑:
使用 FLEX:
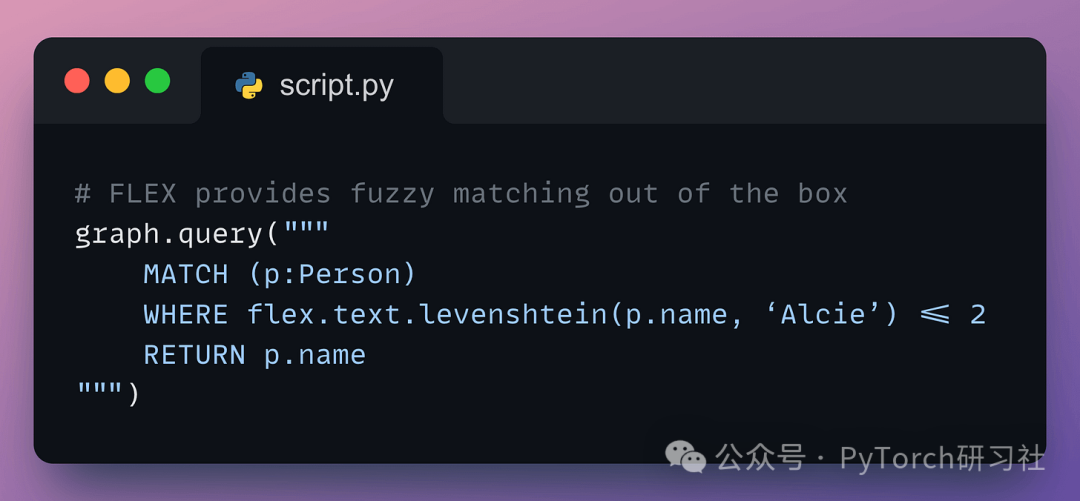
FLEX 内置了以下功能:
- 字符串匹配 (模糊匹配、语音匹配、正则表达式)
- 数据清洗与归一化
- 统计运算
- 时间序列分析
无需编写任何自定义代码。
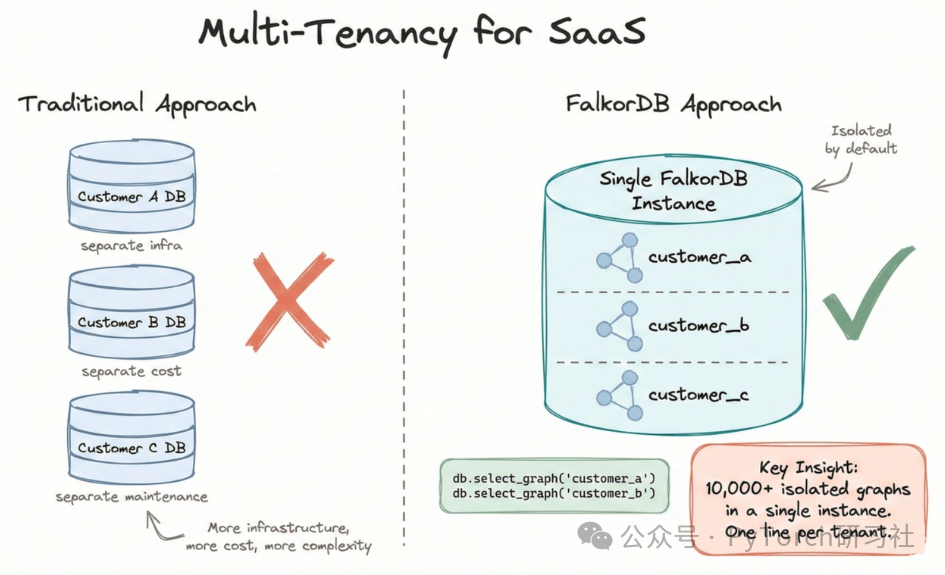
为 SaaS 而生
如果你在构建一个 SaaS 产品 ,那么每个客户都需要 数据隔离 的存储空间。
传统做法: 为每个客户单独启动一个数据库实例:基础设施更多、成本更高、系统更复杂。
FalkorDB 支持在 单个实例中运行 10000+ 个相互隔离的图 :
为什么这对 AI 智能体很重要?
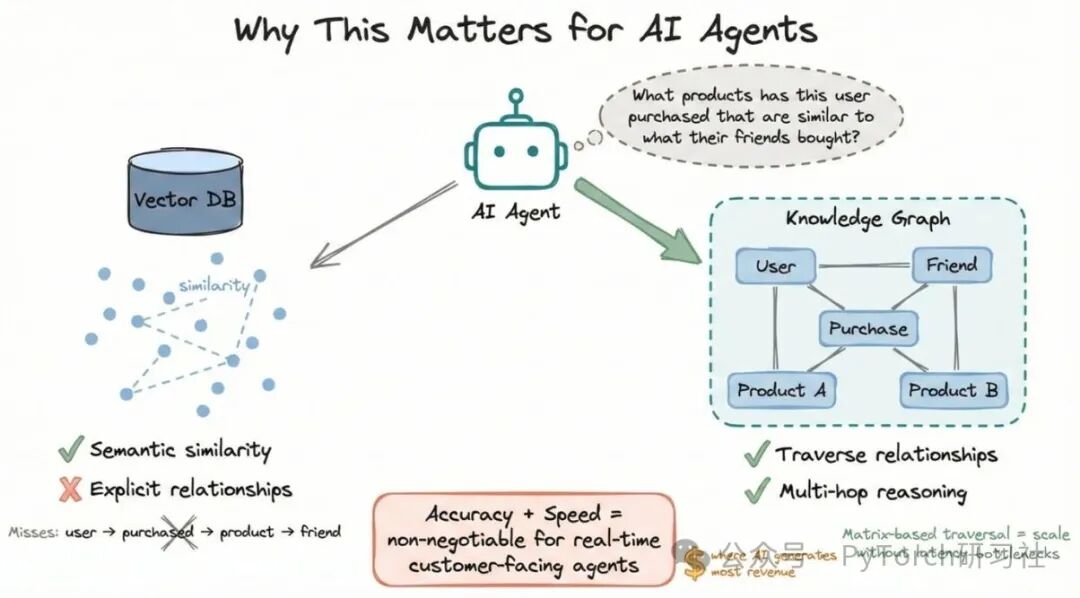
向量数据库可以捕捉 语义相似性 ,但它们 无法明确表示关系 。举例来说,当你的智能体问:“这个用户购买了哪些产品,这些产品和他们朋友购买的产品相似?”
这类问题需要 遍历关系 ,而不仅仅是计算向量相似度。
知识图谱 正好填补了这个空白。
更重要的是,当智能体需要在成千上万个相互关联的实体之间进行 多跳推理 时,基于矩阵的图遍历方式让你能够 在不受延迟瓶颈限制的情况下 扩展系统。
FalkorDB 对图数据库的处理方式有 根本性的不同 :
- 基于矩阵的遍历,即使图规模扩大也依然高速
- 大规模下响应时间低于 100ms
- 通过 FLEX 提供 内置用户自定义函数(UDF)
- 原生多租户,支持 SaaS 应用
- 完全兼容 OpenCypher
- 100% 开源