SSL 证书生成
Git ssh 异常
报错:Error: Connection closed by 198.18.1.11 port 22 fatal: Could not read from remote repository.
向量数据库性能测试
Milvs Pinecone Pgvector
搜索引擎选型
tail: inotify cannot be used, reverting to polling: Too many open files
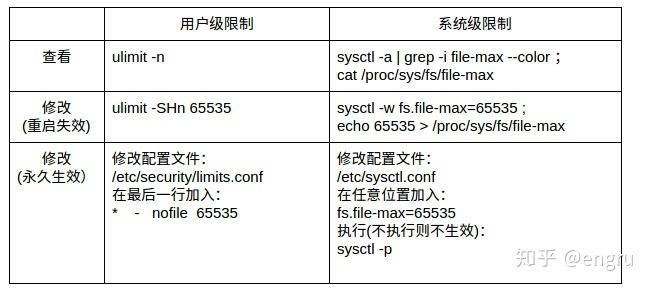
文件描述符限制
有资源的地方就有战争,“文件描述符”也是一种资源,系统中的每个进程都需要有“文件描述符”才能进行改变世界的宏图霸业。世界需要秩序,于是就有了“文件描述符限制”的规定。
如下:
系统级:当前系统可打开的最大数量,通过 fs.file-max 参数可修改
用户级:指定用户可打开的最大数量,修改/etc/security/limits.conf
进程级:单个进程可打开的最大数量,通过fs.nr_open参数可修改
系统级命令
1. file-max
/proc/sys/fs/file-max这个文件决定了系统级别所有进程可以打开的文件描述符的数量限制,如果内核中遇到
VFS: file-max limit <number> reached的信息,那么就提高这个值。设置方式:
# /etc/sysctl.conf fs.file-max = 6553500 sysctl -p2. file-nr
这个是一个状态指示的文件,一共三个值,第一个代表全局已经分配的文件描述符数量,第二个代表自由的文件描述符(待重新分配的),第三个代表总的文件描述符的数量。
cat /proc/sys/fs/file-nr 203136 0 19593935用户级命令
3. nofile
nofile全称
number of open files,最大可打开的文件描述符数量,这个限制是针对用户和进程来说的。3.1. 全局修改,永久生效,需要重启
# /etc/security/limits.conf * soft nofile 65535 * hard nofile 65535soft 指的是当前系统生效的设置值
hard 指的是系统中所能设定的最大值
“-” 指的是同时设置了 soft 和 hard 的值注意:对于ubuntu系统,还需要加载相应的pam模块才能生效
# /etc/pam.d/login # Sets up user limits according to /etc/security/limits.conf # (Replaces the use of /etc/limits in old login) session required pam_limits.so3.2. 临时调整
ulimit -HSn 655350其他命令
4. lsof
$lsof | wc -l 253[~]# lsof COMMAND PID TID USER FD TYPE DEVICE SIZE/OFF NODE NAME systemd 1 root cwd DIR 253,1 4096 2 / systemd 1 root rtd DIR 253,1 4096 2 / systemd 1 root txt REG 253,1 1478184 397653 /usr/lib/systemd/systemd systemd 1 root mem REG 253,1 20032 401603 /usr/lib64/libuuid.so.1.3.0 systemd 1 root mem REG 253,1 252704 401631 /usr/lib64/libblkid.so.1.1.0COMMAD: 命令 PID:进程id TID:线程id USER:用户 FD:文件描述符,比如:cwd当前工作目录;txt程序代码;0标准输入;1标准输出;2标准错误 TYPE:node类型,比如:sock即socket;DIR目录;IPv4等。 DEVICE:磁盘名 SIZE/OFF:文件大小 NODE:文件标识 NAME:文件名称lsof 是列出系统所占用的资源(list open files) 。
lsof /dev/random:列出哪些进程在使用/dev/random(用于产生随机数)
Link to original
bash - tail: inotify cannot be used, reverting to polling: Too many open files - Ask Ubuntu
Permanent solution (preserved across restarts) Adding line:
fs.inotify.max_user_watches=1048576
fs.inotify.max_user_watches=1048576to:
/etc/sysctl.conffixed the limit value permanently (even between restarts).
then do a
sysctl -p开源项目推荐
GitHub - HaujetZhao/QuickCut: Your most handy video processing software
- 定制版本,GitHub - 3dot141/jsoncrack.com
- 防止弹出广告
- 数据库表设计工具
- 可以用来进行数据库的可视化,结合 git 可以做历史记录
GitHub - punkpeye/awesome-mcp-servers: A collection of MCP servers.
- mcp 服务推荐
Redis 可视化
Redis Insight
Redis Insight is our free graphical interface for analyzing Redis data across all operating systems and Redis deployments with the help of our AI assistant, Redis Copilot.REDIS Insight是我们的免费图形接口,用于分析所有操作系统的REDIS数据,并在我们的AI助手Redis Copilot的帮助下重新部署。
状态页框架 Status Pages
Uptime-kuma 是其中支持自部署,页面比较优秀的工具。
GitHub - louislam/uptime-kuma: A fancy self-hosted monitoring tool
商品系统优化
系统架构概览
对于 5 万条商品数据的系统,可以采用以下架构设计进行性能优化:
前端应用 --> CDN --> API网关 --> 应用服务层 --> 缓存层 --> 数据存储层
|
↓
搜索引擎
缓存设计方案
1. 多级缓存架构
设计一个二级缓存系统,减轻数据库压力:
一级缓存(本地缓存)
- 技术选型:Caffeine/Guava Cache
- 适用场景:
- 访问频率极高的热点商品数据
- 几乎不变的基础配置数据
- 特点:
- 读取速度极快(内存级访问)
- 容量有限,只缓存最热数据
- JVM 级别,不能跨服务共享
二级缓存(分布式缓存)
- 技术选型:Redis
- 适用场景:
- 大部分商品数据
- 需要跨服务共享的数据
- 列表、分类等聚合数据
- 特点:
- 读取速度快(网络 IO)
- 容量大,可集群扩展
- 支持丰富的数据结构
2. Redis 缓存设计详解
数据结构选择
| 数据类型 | 使用场景 | 示例 |
|---|---|---|
| Hash | 商品基本信息 | product:10001 → {id, name, price, …} |
| String | 简单键值对 | product:view:10001 → 访问计数 |
| List | 最新商品、推荐列表 | new:products → [pid1, pid2, …] |
| Sorted Set | 排序列表、排行榜 | hot:products → [(pid1,score1), …] |
| Set | 标签、分类关联 | tag:手机 → [pid1, pid2, …] |
具体缓存策略
-
单个商品详情缓存
HMSET product:10001 id 10001 name "iPhone 14" price 6999 description "..." -
分类商品列表缓存
ZADD category:手机 score1 10001 score2 10002 ... -
热门商品排行
ZADD hot:products viewCount1 10001 viewCount2 10002 ... -
搜索结果缓存
SET search:手机:1:20 "[{...},{...},...]" EX 3600
3. 缓存更新策略
采用多种策略结合方式:
- Cache-Aside 模式:先更新数据库,再删除缓存
- 定时更新:对于热门商品,定时刷新缓存
- 过期时间:根据数据更新频率设置不同 TTL
- 商品基本信息:1 天
- 热门商品排行:1 小时
- 搜索结果:10 分钟
代码示例
二级缓存实现示例
@Service
public class ProductService {
@Autowired
private CacheManager localCache; // Caffeine本地缓存
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private ProductRepository productRepository;
public Product getProduct(Long id) {
// 1. 查询本地缓存
Product product = localCache.getIfPresent("product:" + id);
if (product != null) {
return product;
}
// 2. 查询Redis缓存
product = redisTemplate.opsForHash().entries("product:" + id);
if (product != null) {
// 回填本地缓存
localCache.put("product:" + id, product);
return product;
}
// 3. 查询数据库
product = productRepository.findById(id);
if (product != null) {
// 回填Redis缓存
redisTemplate.opsForHash().putAll("product:" + id,
convertToMap(product));
redisTemplate.expire("product:" + id, 1, TimeUnit.DAYS);
// 回填本地缓存
localCache.put("product:" + id, product);
}
return product;
}
// 更新商品时的缓存处理
public void updateProduct(Product product) {
// 先更新数据库
productRepository.save(product);
// 删除缓存
redisTemplate.delete("product:" + product.getId());
localCache.invalidate("product:" + product.getId());
// 更新相关联的列表缓存
// ...
}
}性能优化建议
-
数据库优化
- 创建合适的索引(商品 ID、分类 ID、标签等)
- 读写分离
- 批量操作减少数据库交互
-
Redis 优化
- 使用 Pipeline 减少网络往返
- 避免大 key,拆分过大的集合
- Redis 集群提高可用性
-
应用层优化
- 异步处理非实时数据更新
- 预热缓存避免冷启动
- 限流防止缓存雪崩
-
前端优化
- CDN 加速
- 数据按需加载
- 前端缓存策略
系统扩展性考虑
- 当前 5 万商品级别,此方案足够支撑
- 数据量增长到百万级时,考虑引入:
- ES 搜索引擎
- 数据分片
- 读写分离集群
以上设计既考虑了当前 5 万商品的需求,也为未来系统扩展预留了空间,通过多级缓存可以有效提升系统性能和用户体验。